文章目录
MySQL主从复制的原理与实操
主从复制原理
当一个MySQL数据库服务器负载过重或者需要横向扩展时,主从复制是一种非常常见的解决方案。MySQL主从复制是将一个数据库服务器(master)的数据复制到其他数据库服务器(salve)的过程。在这个过程中,主服务器上的所有更改都将被自动复制到从服务器,从而实现数据同步。
下面是MySQL主从复制的基本原理:
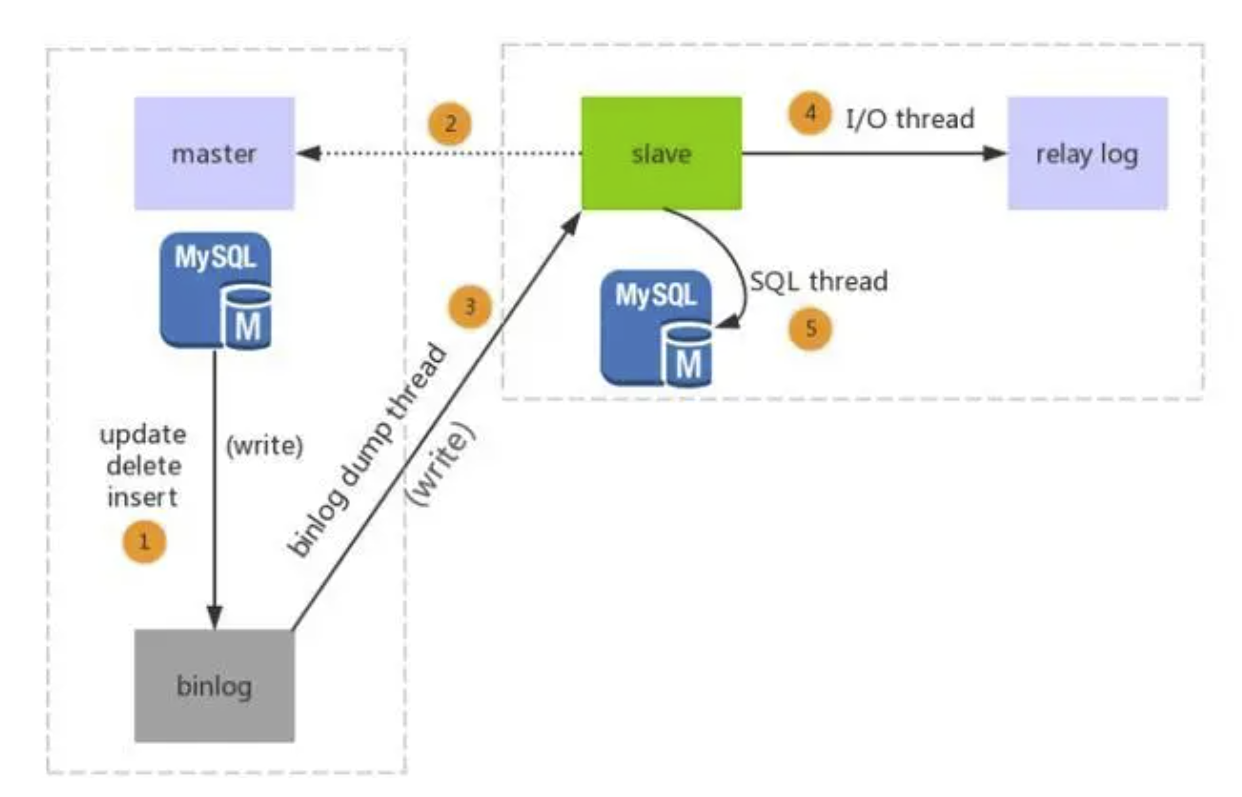
- 主服务器记录二进制日志(Binary Log)。
- 从服务器连接到主服务器并请求复制数据。主服务器创建一个复制线程,将复制数据发送给从服务器。从服务器通过IO Thread(输入/输出线程)连接到主服务器,并从主服务器请求二进制日志文件。主服务器在二进制日志中记录所有的更改,然后将这些更改发送给从服务器。IO Thread 将这些更改写入从服务器上的中继日志文件(Relay Log)。
- 从服务器执行中继日志中的更改。SQL Thread(SQL 线程)从中继日志中读取数据并将其应用到从服务器上。SQL Thread 按照主服务器的顺序执行每个更改,以确保从服务器与主服务器保持同步。
- 当有新的更改发生时,主服务器将记录更改并将其发送到所有连接的从服务器。从服务器将这些更改写入中继日志文件并应用这些更改。
- 如果从服务器出现问题,可以通过将一个新的从服务器连接到主服务器来重新启动复制进程。
需要注意的是,MySQL主从复制并不是一种高可用性解决方案。如果主服务器宕机,从服务器将不能自动接管服务。因此,在设计高可用性系统时,可能需要使用其他技术。
MySQL主从复制的高级应用
- 复制方式:MySQL主从复制可以通过同步或异步的方式进行复制。在同步复制中,主服务器必须等待所有的从服务器确认它们已成功地接收并应用了所有更改,才能提交更改。这确保了数据的一致性,但会降低系统的性能。在异步复制中,主服务器无需等待从服务器确认,因此可以提高系统的性能,但可能会导致数据不一致。
- 复制过滤:在进行主从复制时,可以使用复制过滤来控制哪些更改将被复制到从服务器。例如,可以指定仅复制特定的数据库、表或列。
- 自动故障转移:MySQL主从复制本身并不支持自动故障转移,因此在设计高可用性系统时,需要使用其他技术,例如基于虚拟IP地址的故障转移技术或者结合使用MySQL主从复制和集群技术来实现。
- 主从切换:在某些情况下,需要手动切换主从角色,例如当主服务器出现故障时,需要手动将从服务器提升为主服务器。在进行主从切换时,需要注意切换的正确性以及避免数据不一致。
总的来说,MySQL主从复制是一种非常强大和灵活的技术,它可以实现数据的高可用性、负载均衡和数据备份等目的。但是在使用时需要了解其原理和细节,以避免出现潜在的问题。
MySQL主从复制实操(一主两从)
环境准备
两台机器一主两从。
主master:IP 192.168.133.129
从slave1:IP 192.168.133.130
从slave2:IP 192.168.133.131
master配置
-
[mysqld] log_bin = mysql-bin server_id = 1 systemctl restart mysqld # 重启服务 -
建立同步账号
mysql> grant replication slave on *.* to 'rep'@'192.168.133.%' identified by '123456'; mysql> show grants for 'rep'@'192.168.133.%'; -
通过mysqldump同步三个数据库中的db
# 锁表设置只读为后面备份准备,注意生产环境要提前申请停机时间; mysql> flush tables with read lock; # 提示:如果超过设置时间不操作会自动解锁。 mysql> show variables like '%timeout%'; # 测试锁表后是否可以创建数据库: # 查看主库状态,即当前日志文件名和二进制日志偏移量 mysql> show master status; # 备份数据库数据 mysqldump -uroot -p -A -B ···> /server/backup/mysql_bak.$(date +%F).sql -
解锁
mysql> unlock tables; -
主库备份数据上传到从库
scp /server/backup/mysql_bak.2015-11-18.sql.gz 192.168.95.130:/server/backup/
slave设置
-
1)设置server-id值并关闭binlog参数
[mysqld] log_bin = mysql-bin server_id = 130 # 重启数据库 systemctl restart mysqld -
还原从主库备份数据
cd /server/backup/ mysql -uroot -p < /server/backup/mysql_bak.$(date +%F).sql # 检查还原: mysql -uroot -p -e 'show databases;' -
设定从主库同步
mysql> change master to MASTER_HOST='192.168.95.120', MASTER_PORT=3306, MASTER_USER='rep', MASTER_PASSWORD='123456', MASTER_LOG_FILE='mysql-bin.000003', MASTER_LOG_POS=329; -
启动从库同步开关
mysql> start slave; # 检查状态: mysql> show slave status\G # Slave_IO_Running: IO线程是否打开 YES/No/NULL # Slave_SQL_Running: SQL线程是否打开 YES/No/NULL
MySQL读写分离配置(一主两从)
创建数据源
# 添加读写的数据源
/*+ mycat:createDataSource{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"m1",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://127.0.0.1:3306/db1? useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8", "user":"root",
"weight":0
} */;
# 添加读的数据源
/*+ mycat:createDataSource{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"m1s1",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://127.0.0.1:3307/db1? useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user":"root",
"weight":0 }
*/;
/*+ mycat:createDataSource{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"m1s2",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://127.0.0.1:3308/db1? useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user":"root",
"weight":0 }
*/;
查询数据源
/*+ mycat:showDataSources{
} */
7.3 创建集群
/*! mycat:createCluster{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
}, "masters":[
"m1 " ],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"m1s1"
"m1s2"
],
"switchType":"SWITCH"
} */;
查询集群
/*+ mycat:showClusters{
} */
创建逻辑库
CREATE DATABASE db1 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
修改逻辑库的数据源
修改conf/schemas/db1.schema.json
vim /data/mycat/conf/schemas/db1.schema.json
在里面添加 "targetName":"prototype",
[root@node4 mysqlms]# cat /data/mycat/conf/schemas/db1.schema.json
{
"customTables":{
},
"globalTables":{
},
"normalProcedures":{
},
"normalTables":{
},
"schemaName":"db1",
"shardingTables":{
},
"targetName":"prototype",
"views":{
}
}
测试读写分离是否成功
在MyCAT里面测试
重启MyCAT:
[root@node4 mysqlms]# cd /data/mycat/bin/
[root@node4 bin]# ./mycat restart
1)在MyCAT里面创建一个sys_user表:
use db1;
CREATE TABLE SYS_USER( ID BIGINT PRIMARY KEY, USERNAME VARCHAR(200) NOT NULL,ADDRESS VARCHAR(500));
2)通过注释生成物理库和物理表:
如果物理表不存在,在 MyCAT2 能正常启动的情况下,根据当前配置自动创建分片表,全局表和物理 表:
/*+ mycat:repairPhysicalTable{
} */;
3)查看后端物理库
4)在MyCAT里面向sys_user表添加一条数据:
INSERT INTO SYS_USER(ID,USERNAME,ADDRESS) VALUES(1,"XIAOMING","WUHAN");
5)修改MySQL里面的让数据不一样
6)在MyCAT里面查询数据,会发现每次查询的结果不一样

文章评论