当前位置:网站首页>How to select the evaluation index of classification model
How to select the evaluation index of classification model
2020-11-06 01:14:07 【Artificial intelligence meets pioneer】
author |MUSKAN097 compile |VK source |Analytics Vidhya
brief introduction
You've successfully built the classification model . What should you do now ? How do you evaluate the performance of the model , That is, the performance of the model in predicting the results . To answer these questions , Let's use a simple case study to understand the metrics used in evaluating classification models .
Let's take a deeper look at concepts through case studies
In this era of Globalization , People often travel from one place to another . Because the passengers are waiting in line 、 Check in 、 Visit food suppliers and use toilets and other facilities , Airports can bring risks . Tracking passengers carrying the virus at the airport helps prevent the spread of the virus .
Think about it , We have a machine learning model , Divide the passengers into COVID Positive and negative . When making classification prediction , There are four possible types of results :
Real examples (TP): When you predict that an observation belongs to a class , And it actually belongs to that category . under these circumstances , In other words, it is predicted that COVID Positive and actually positive passengers .
True counter example (TN): When you predict that an observation does not belong to a class , It doesn't really belong to that category either . under these circumstances , In other words, the prediction is not COVID positive ( negative ) And it's not really COVID positive ( negative ) Passengers .
False positive example (FalsePositive,FP): When you predict that an observation belongs to a certain class , When it doesn't belong to this class . under these circumstances , In other words, it is predicted that COVID Positive, but it's not COVID positive ( negative ) Passengers .
False counter example (FN): When you predict that an observation does not belong to a class , And it actually belongs to that category . under these circumstances , In other words, the prediction is not COVID positive ( negative ) And it's actually COVID Positive passengers .
Confusion matrix
To better visualize the performance of the model , These four results are plotted on the confusion matrix .
Accuracy
Yes ! You're right , We want our model to focus on the real positive and negative examples . Accuracy is an indicator , It gives the score our model correctly predicts . Formally , Accuracy has the following definition :
Accuracy = Correct prediction number / The total number of predictions .
Now? , Let's consider that on average there are 50000 Passengers travel . Among them is 10 Yes COVID positive .
An easy way to improve accuracy is to classify each passenger as COVID negative . So our confusion matrix is as follows :
The accuracy of this case is :
Accuracy =49990/50000=0.9998 or 99.98%
magical !! That's right ? that , This really solves the problem of classifying correctly COVID The purpose of the positive passengers ?
For this particular example , We tried to mark the passengers as COVID Positive and negative , Hope to be able to identify the right passengers , I can simply mark everyone as COVID Negative to get 99.98% The accuracy of .
obviously , It's a more accurate method than we've seen in any model . But that doesn't solve the purpose . The purpose here is to identify COVID Positive passengers . under these circumstances , Accuracy is a terrible measure , Because it's easy to get very good accuracy , But that's not what we're interested in .
So in this case , Accuracy is not a good way to evaluate models . Let's take a look at a very popular measure , It's called the recall rate .
Recall rate ( Sensitivity or true case rate )
The recall rate gives you a score that you correctly identified as positive .
Now? , This is an important measure . Of all the positive passengers , What is the score you correctly identified . Back to our old strategy , Mark every passenger negative , So the recall rate is zero .
Recall = 0/10 = 0
therefore , under these circumstances , Recall rate is a good measure . It said , Identify every passenger as COVID The terrible strategy of negativity leads to zero recall . We want to maximize the recall rate .
As another positive answer to each of the above questions , Please consider it COVID Every question of . Everyone goes into the airport , They're labeled positive by models . It's not good to put a positive label on every passenger , Because before they board the plane , The actual cost of investigating each passenger is enormous .
The confusion matrix is as follows :
The recall rate will be :
Recall = 10/(10+0) = 1
It's a big problem . therefore , The conclusion is that , Accuracy is a bad idea , Because putting negative labels on everyone can improve accuracy , But hopefully the recall rate is a good measure in this case , But then I realized , Putting a positive label on everyone also increases the recall rate .
So independent recall rates are not a good measure .
Another method of measurement is called accuracy
accuracy
The accuracy gives the fraction of all predicted positive results that are correctly identified as positive .
Considering our second wrong strategy , I'm going to mark each passenger as positive , The accuracy will be :
Precision = 10 / (10 + 49990) = 0.0002
Although this wrong strategy has a good recall value 1, But it has a terrible accuracy value 0.0002.
This shows that recall alone is not a good measure , We need to think about accuracy .
Consider another situation ( This will be the last case , by my troth :P) Mark the top passengers as COVID positive , That is to mark the disease COVID The most likely passenger . Suppose we have only one such passenger . The confusion matrix in this case is :
The accuracy is :1/(1+0)=1
under these circumstances , The accuracy is very good , But let's check the recall rate :
Recall = 1 / (1 + 9) = 0.1
under these circumstances , The accuracy is very good , But the recall value is low .
| scene | Accuracy | Recall rate | accuracy |
|---|---|---|---|
| Classify all passengers as negative | high | low | low |
| Classify all passengers as positive | low | high | low |
| The top passengers are marked with COVID positive | high | low | low |
In some cases , We are very sure that we want to maximize recall or accuracy , And at the cost of others . In this case of marking passengers , We really want to be able to correctly predict COVID Positive passengers , Because it's very expensive not to predict the accuracy of passengers , Because it allows COVID Positive people passing through can lead to an increase in transmission . So we're more interested in the recall rate .
Unfortunately , You can't have both : Improving accuracy will reduce recall , vice versa . This is called accuracy / Recall rate tradeoff .
Accuracy / Recall rate tradeoff
The probability of output of some classification models is between 0 and 1 Between . Before we divide the passengers into COVID In positive and negative cases , We want to avoid missing out on the actual positive cases . especially , If a passenger is really positive , But our model doesn't recognize it , It would be very bad , Because the virus is likely to spread by allowing these passengers to board . therefore , Even if there's a little doubt, there's COVID, We have to put a positive label on it, too .
So our strategy is , If the output probability is greater than 0.3, We mark them as COVID positive .
This leads to higher recall rates and lower accuracy .
Consider the opposite , When we determine that the passenger is positive , We want to classify passengers as positive . We set the probability threshold to 0.9, When the probability is greater than or equal to 0.9 when , Classify passengers as positive , Otherwise it's negative .
So generally speaking , For most classifiers , When you change the probability threshold , There will be a trade-off between recall and accuracy .
If you need to compare different models with different exact recall values , It is usually convenient to combine precision and recall into a single metric . Right !! We need an index that considers both recall and accuracy to calculate performance .
F1 fraction
It is defined as the harmonic mean of model accuracy and recall rate .
You must wonder why the harmonic average is not the simple average ? We use harmonic means because it is insensitive to very large values , It's not like a simple average .
For example , We have a precision of 1 Model of , The recall rate is 0 A simple average value is given 0.5,F1 The score is 0. If one of the parameters is low , The second parameter is in F1 Scores don't matter anymore .F1 Scores tend to be classifiers with similar accuracy and recall rate .
therefore , If you want to strike a balance between accuracy and recall ,F1 Score is a better measure .
ROC/AUC curve
ROC It's another common assessment tool . It gives the model in 0 To 1 Between the sensitivity and specificity of each possible decision point . For classification problems with probabilistic outputs , The output probability can be converted into a threshold . So by changing the threshold , You can change some numbers in the confusion matrix . But the most important question here is , How to find the right threshold ?
For every possible threshold ,ROC The rate of false positive cases and true cases of curve drawing .
The false positive rate is : The proportion of counter examples wrongly classified as positive .
True case rate : The proportion of positive examples correctly predicted as positive examples .
Now? , Consider a low threshold . therefore , Of all the probabilities in ascending order , lower than 0.1 Is considered negative , higher than 0.1 All are considered positive . The selection threshold is free
But if you set your threshold high , such as 0.9.
The following is the first mock exam for the same model under different thresholds ROC curve .
As can be seen from the above figure , The true case rate is increasing at a higher rate , But at some threshold ,TPR It starts to decrease . Every time you add TPR, We have to pay a price —FPR An increase in . In the initial stage ,TPR The increase is higher than FPR
therefore , We can choose TPR High and high FPR Low threshold .
Now? , Let's see TPR and FPR The different values of the model tell us what .
For different models , We're going to have different ROC curve . Now? , How to compare different models ? As can be seen from the graph above , The curve above represents that the model is good . One way to compare classifiers is to measure ROC The area under the curve .
AUC( Model 1)>AUC( Model 2)>AUC( Model 2)
So the model 1 It's the best .
summary
We learned about the different metrics used to evaluate the classification model . When to use which indicators depends largely on the nature of the problem . So now back to your model , Ask yourself what the main purpose of your solution is , Choose the right indicator , And evaluate your model .
Link to the original text :https://www.analyticsvidhya.com/blog/2020/10/how-to-choose-evaluation-metrics-for-classification-model/
Welcome to join us AI Blog station : http://panchuang.net/
sklearn Machine learning Chinese official documents : http://sklearn123.com/
Welcome to pay attention to pan Chuang blog resource summary station : http://docs.panchuang.net/
版权声明
本文为[Artificial intelligence meets pioneer]所创,转载请带上原文链接,感谢
边栏推荐
- C++ 数字、string和char*的转换
- C++学习——centos7上部署C++开发环境
- C++学习——一步步学会写Makefile
- C++学习——临时对象的产生与优化
- C++学习——对象的引用的用法
- C++编程经验(6):使用C++风格的类型转换
- Won the CKA + CKS certificate with the highest gold content in kubernetes in 31 days!
- C + + number, string and char * conversion
- C + + Learning -- capacity() and resize() in C + +
- C + + Learning -- about code performance optimization
猜你喜欢
-
C + + programming experience (6): using C + + style type conversion
-

Latest party and government work report ppt - Park ppt
-
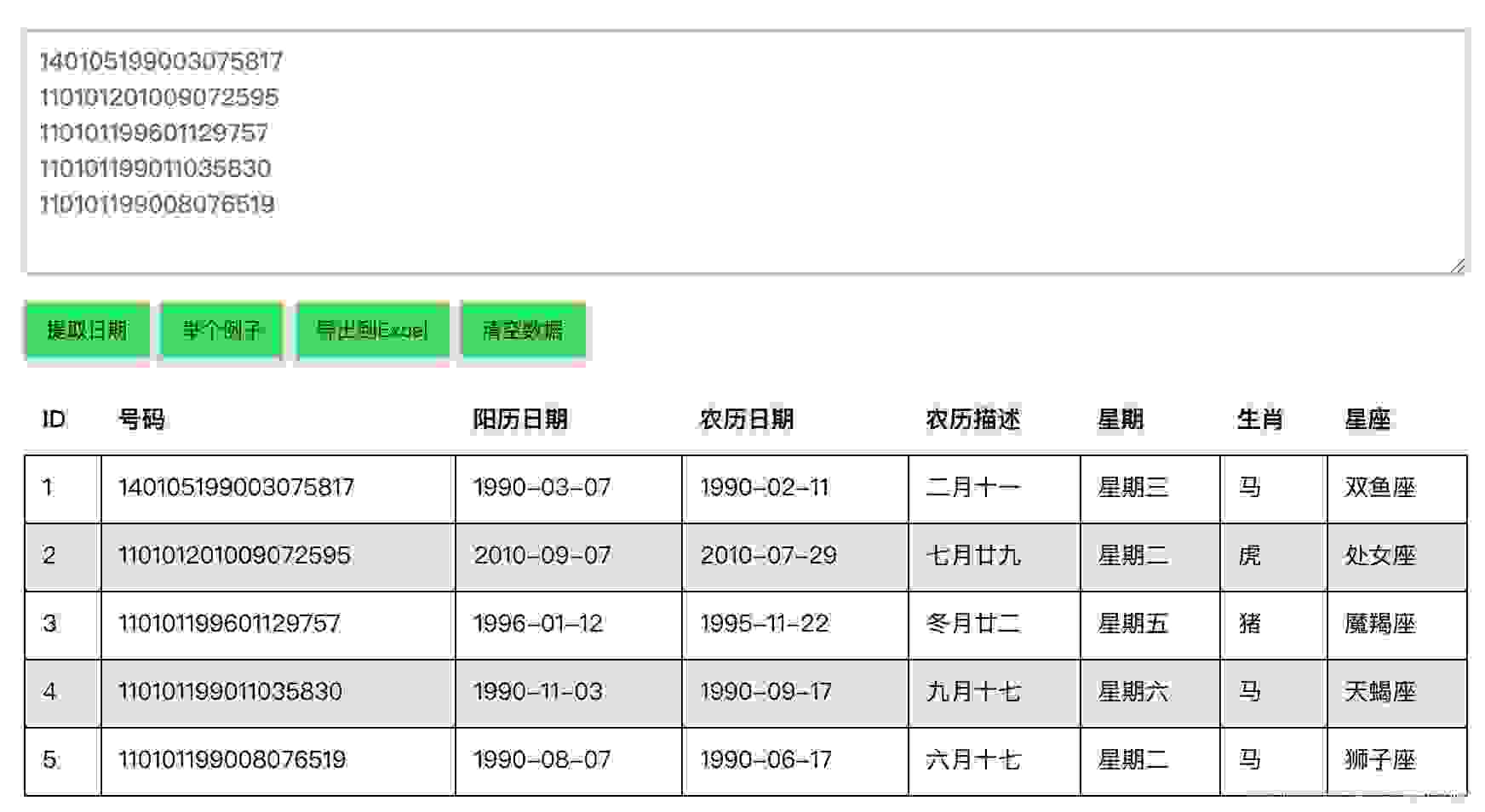
在线身份证号码提取生日工具
-
Online ID number extraction birthday tool
-
️野指针?悬空指针?️ 一文带你搞懂!
-
Field pointer? Dangling pointer? This article will help you understand!
-
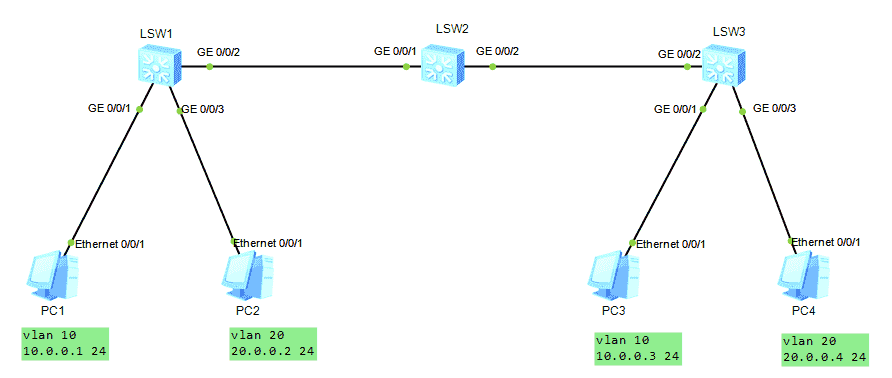
HCNA Routing&Switching之GVRP
-
GVRP of hcna Routing & Switching
-

Seq2Seq实现闲聊机器人
-
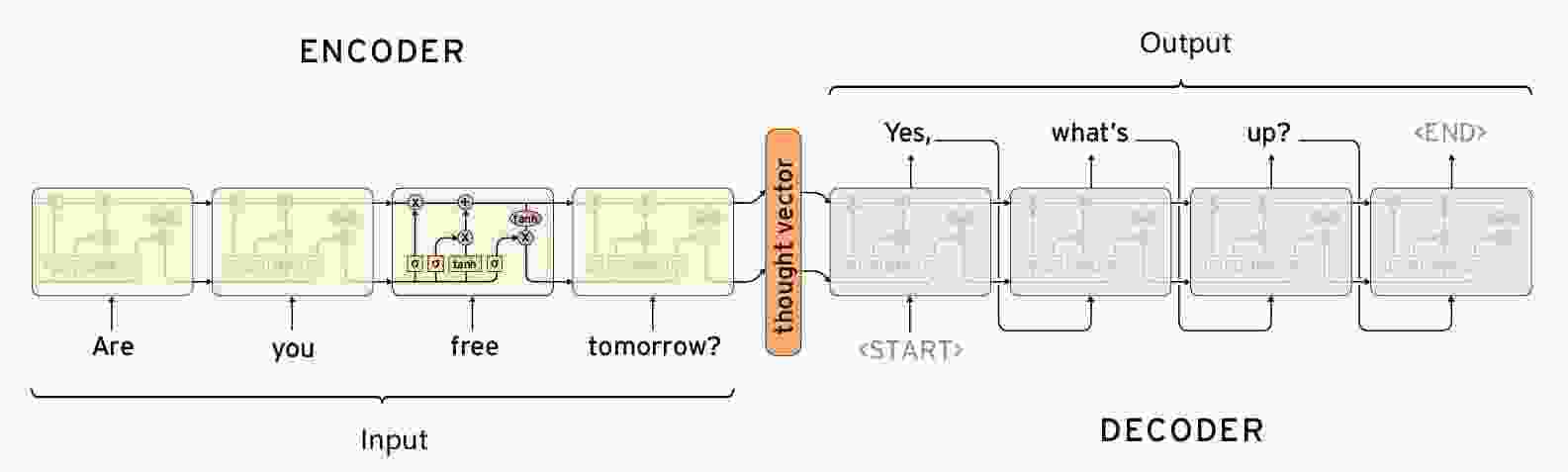
【闲聊机器人】seq2seq模型的原理
随机推荐
- LeetCode 91. 解码方法
- Seq2seq implements chat robot
- [chat robot] principle of seq2seq model
- Leetcode 91. Decoding method
- HCNA Routing&Switching之GVRP
- GVRP of hcna Routing & Switching
- HDU7016 Random Walk 2
- [Code+#1]Yazid 的新生舞会
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- HDU7016 Random Walk 2
- [code + 1] Yazid's freshman ball
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- Qt Creator 自动补齐变慢的解决
- HALCON 20.11:如何处理标定助手品质问题
- HALCON 20.11:标定助手使用注意事项
- Solution of QT creator's automatic replenishment slowing down
- Halcon 20.11: how to deal with the quality problem of calibration assistant
- Halcon 20.11: precautions for use of calibration assistant
- “十大科学技术问题”揭晓!|青年科学家50²论坛
- "Top ten scientific and technological issues" announced| Young scientists 50 ² forum
- 求反转链表
- Reverse linked list
- js的数据类型
- JS data type
- 记一次文件读写遇到的bug
- Remember the bug encountered in reading and writing a file
- 单例模式
- Singleton mode
- 在这个 N 多编程语言争霸的世界,C++ 究竟还有没有未来?
- In this world of N programming languages, is there a future for C + +?
- es6模板字符
- js Promise
- js 数组方法 回顾
- ES6 template characters
- js Promise
- JS array method review
- 【Golang】️走进 Go 语言️ 第一课 Hello World
- [golang] go into go language lesson 1 Hello World