当前位置:网站首页>Dapr實現分散式有狀態服務的細節
Dapr實現分散式有狀態服務的細節
2020-11-06 01:35:51 【itread01】
Dapr是為雲上環境設計的跨語言, 事件驅動, 可以便捷的構建微服務的系統. balabala一堆, 有興趣的小夥伴可以去了解一下.
Dapr提供有狀態和無狀態的微服務. 大部分人都是做無狀態服務(微服務)的, 只是某些領域無狀態並不好使, 因為開銷實在是太大了; 有狀態服務有固定的場景, 就是要求開銷小, 延遲和吞吐都比較高. 廢話少說, 直接來看Dapr是怎麼實現有狀態服務的.
先來了解一下有狀態服務:
1. 穩定的路由
傳送給A伺服器的請求, 不能發給B伺服器, 否則就是無狀態的
2. 狀態
狀態儲存在自己伺服器內部, 而不是遠端儲存, 這一點和無狀態有很明顯的區別, 所以無狀態服務需要用redis這種東西加速, 有狀態不需要
3. 處理是單執行緒
狀態一般來講比較複雜, 想要對一個比較複雜的東西進行並行的計算是比較困難的; 當然A和B的邏輯之間沒有關係, 其實是可以並行的, 但是A自己本身的邏輯執行需要序列執行.
對於一個有狀態服務來講(dapr), 實現23實際上是很輕鬆的, 甚至有一些是使用者需要實現的東西, 所以1才是關鍵, 當前這個訊息(請求)需要被髮送到哪個伺服器上面處理才是最關鍵的, 甚至決定了他是什麼系統.
決定哪個請求的目標地址, 這個東西在分散式系統裡面叫Placement, 有時候也叫Naming. TiDB裡面有一個Server叫PlacementDriver, 簡稱PD, 其實就是在幹同樣的事情.
好了, 開始研究Dapr的Placement是怎麼實現的.
有一個Placement的程序, 2333, 目錄cmd/placement, 就看他了
func main() {
log.Infof("starting Dapr Placement Service -- version %s -- commit %s", version.Version(), version.Commit())
cfg := newConfig()
// Apply options to all loggers.
if err := logger.ApplyOptionsToLoggers(&cfg.loggerOptions); err != nil {
log.Fatal(err)
}
log.Infof("log level set to: %s", cfg.loggerOptions.OutputLevel)
// Initialize dapr metrics for placement.
if err := cfg.metricsExporter.Init(); err != nil {
log.Fatal(err)
}
if err := monitoring.InitMetrics(); err != nil {
log.Fatal(err)
}
// Start Raft cluster.
raftServer := raft.New(cfg.raftID, cfg.raftInMemEnabled, cfg.raftBootStrap, cfg.raftPeers)
if raftServer == nil {
log.Fatal("failed to create raft server.")
}
if err := raftServer.StartRaft(nil); err != nil {
log.Fatalf("failed to start Raft Server: %v", err)
}
// Start Placement gRPC server.
hashing.SetReplicationFactor(cfg.replicationFactor)
apiServer := placement.NewPlacementService(raftServer)
可以看到main函式裡面啟動了一個raft server, 一般這樣的話, 就說明在某些能力方面做到了強一致性.
raft庫用的是consul實現的raft, 而不是etcd, 因為etcd的raft不是庫, 只能是一個伺服器(包括etcd embed), 你不能定製裡面的協議, 你只能使用etcd提供給你的client來訪問他. 這一點etcd做的非常不友好.
如果用raft庫來做placement, 那麼協議可以定製, 可以找Apply相關的函式, 因為raft狀態機只是負責log的一致性, log即訊息, 訊息的處理則表現出來狀態, Apply函式就是需要使用者做訊息處理的地方. 幸虧之前有做過MIT 6.824的lab, 對這個稍微有一點了解.
// Apply log is invoked once a log entry is committed.
func (c *FSM) Apply(log *raft.Log) interface{} {
buf := log.Data
cmdType := CommandType(buf[0])
if log.Index < c.state.Index {
logging.Warnf("old: %d, new index: %d. skip apply", c.state.Index, log.Index)
return nil
}
var err error
var updated bool
switch cmdType {
case MemberUpsert:
updated, err = c.upsertMember(buf[1:])
case MemberRemove:
updated, err = c.removeMember(buf[1:])
default:
err = errors.New("unimplemented command")
}
if err != nil {
return err
}
return updated
}
在pkg/placement/raft資料夾下面找到raft相關的程式碼, fsm.go裡面有對訊息的處理函式.
可以看到, 訊息的處理非常簡單, 裡面只有MemberUpsert, 和MemberRemove兩個訊息. FSM狀態機內儲存的狀態只有:
// DaprHostMemberState is the state to store Dapr runtime host and
// consistent hashing tables.
type DaprHostMemberState struct {
// Index is the index number of raft log.
Index uint64
// Members includes Dapr runtime hosts.
Members map[string]*DaprHostMember
// TableGeneration is the generation of hashingTableMap.
// This is increased whenever hashingTableMap is updated.
TableGeneration uint64
// hashingTableMap is the map for storing consistent hashing data
// per Actor types.
hashingTableMap map[string]*hashing.Consistent
}
很明顯, 這裡面只有DaprHostMember這個有用的資訊, 而DaprHostMember就是叢集內的節點.
這裡可以分析出來, Dapr通過Raft協議來維護了一個強一致性的Membership, 除此之外什麼也沒幹....據我的朋友說, 跟Orleans是有一點類似的, 只是Orleans是AP系統.
再通過對一致性Hash的分析, 可以看到:
func (a *actorsRuntime) lookupActorAddress(actorType, actorID string) (string, string) {
if a.placementTables == nil {
return "", ""
}
t := a.placementTables.Entries[actorType]
if t == nil {
return "", ""
}
host, err := t.GetHost(actorID)
if err != nil || host == nil {
return "", ""
}
return host.Name, host.AppID
}
通過 ActorType和ActorID到一致性的Hash表中去找host, 那個GetHost實現就是一致性Hash表實現的.
Actor RPC Call的實現:
func (a *actorsRuntime) Call(ctx context.Context, req *invokev1.InvokeMethodRequest) (*invokev1.InvokeMethodResponse, error) {
if a.placementBlock {
<-a.placementSignal
}
actor := req.Actor()
targetActorAddress, appID := a.lookupActorAddress(actor.GetActorType(), actor.GetActorId())
if targetActorAddress == "" {
return nil, errors.Errorf("error finding address for actor type %s with id %s", actor.GetActorType(), actor.GetActorId())
}
var resp *invokev1.InvokeMethodResponse
var err error
if a.isActorLocal(targetActorAddress, a.config.HostAddress, a.config.Port) {
resp, err = a.callLocalActor(ctx, req)
} else {
resp, err = a.callRemoteActorWithRetry(ctx, retry.DefaultLinearRetryCount, retry.DefaultLinearBackoffInterval, a.callRemoteActor, targetActorAddress, appID, req)
}
if err != nil {
return nil, err
}
return resp, nil
}
通過剛才我們看到loopupActorAddress函式找到的Host, 然後判斷是否是在當前Host宿主內, 否則就傳送到遠端, 對當前宿主做了優化, 實際上沒雞兒用, 因為分散式系統裡面, 一般都會有很多個host, 在當前host內的概率實際上是非常低的.
從這邊, 我們大概就能分析到全貌, 即Dapr實現分散式有狀態服務的細節:
1. 通過Consul Raft庫維護Membership
2. 叢集和Placement元件通訊, 獲取到Membership
3. 尋找Actor的演算法實現在Host內, 而不是Placement元件. 通過ActorType找到可以提供某種服務的Host, 然後組成一個一致性Hash表, 到該表內查詢Host, 進而轉發請求
對Host內一致性Hash表的查詢引用, 找到了修改內容的地方:
func (a *actorsRuntime) updatePlacements(in *placementv1pb.PlacementTables) {
a.placementTableLock.Lock()
defer a.placementTableLock.Unlock()
if in.Version != a.placementTables.Version {
for k, v := range in.Entries {
loadMap := map[string]*hashing.Host{}
for lk, lv := range v.LoadMap {
loadMap[lk] = hashing.NewHost(lv.Name, lv.Id, lv.Load, lv.Port)
}
c := hashing.NewFromExisting(v.Hosts, v.SortedSet, loadMap)
a.placementTables.Entries[k] = c
}
a.placementTables.Version = in.Version
a.drainRebalancedActors()
log.Infof("placement tables updated, version: %s", in.GetVersion())
a.evaluateReminders()
}
}
從這幾行程式碼可以看出, 版本不不一樣, 就會全更新, 而且還會進行rehash, 就是a.drainRebalanceActors.
如果學過資料結構, 那麼肯定學到過一種東西叫HashTable, HashTable在擴容的時候需要rehash, 需要構建一個更大的table, 然後把所有元素重新放進去, 位置會和原先的大不一樣. 而一致性Hash可以解決全rehash的情況, 只讓部分內容rehash, 失效的內容會比較少.
但是, 凡事都有一個但是, 所有的節點都同時rehash還好, 可一個分散式系統怎麼做到所有node都同時rehash, 很顯然是做不到的, 所以Dapr維護的Actor Address目錄, 是最終一致的, 也就是系統裡面會存在多個ID相同的Actor(短暫的), 還是會導致不一致.
對dapr/proto/placement/v1/placement.proto檢視, 驗證了我的猜想
// Placement service is used to report Dapr runtime host status.
service Placement {
rpc ReportDaprStatus(stream Host) returns (stream PlacementOrder) {}
}
message PlacementOrder {
PlacementTables tables = 1;
string operation = 2;
}
Host啟動, 就去placement那邊通過gRPC Stream訂閱了叢集的變動. 懶到極點了, 居然是把整個membership傳送過來, 而不是傳送的diff.
總結一下, 從上面的原始碼分析我們可以知道, Dapr的Membership是CP系統, 但是Actor的Placement不是, 是一個最終一致的AP系統. 而TiDB的PD是一個CP系統, 只不過是通過etcd embed做的. 希望對大家有一點幫助.
對我有幫助的, 可能就是Dapr對於Consul raft的使用.
參考:
1. Dapr
2. Etcd Embed
3. Consul Raft
&n
版权声明
本文为[itread01]所创,转载请带上原文链接,感谢
https://www.itread01.com/content/1604595964.html
边栏推荐
- C++ 数字、string和char*的转换
- C++学习——centos7上部署C++开发环境
- C++学习——一步步学会写Makefile
- C++学习——临时对象的产生与优化
- C++学习——对象的引用的用法
- C++编程经验(6):使用C++风格的类型转换
- Won the CKA + CKS certificate with the highest gold content in kubernetes in 31 days!
- C + + number, string and char * conversion
- C + + Learning -- capacity() and resize() in C + +
- C + + Learning -- about code performance optimization
猜你喜欢
-
C + + programming experience (6): using C + + style type conversion
-

Latest party and government work report ppt - Park ppt
-
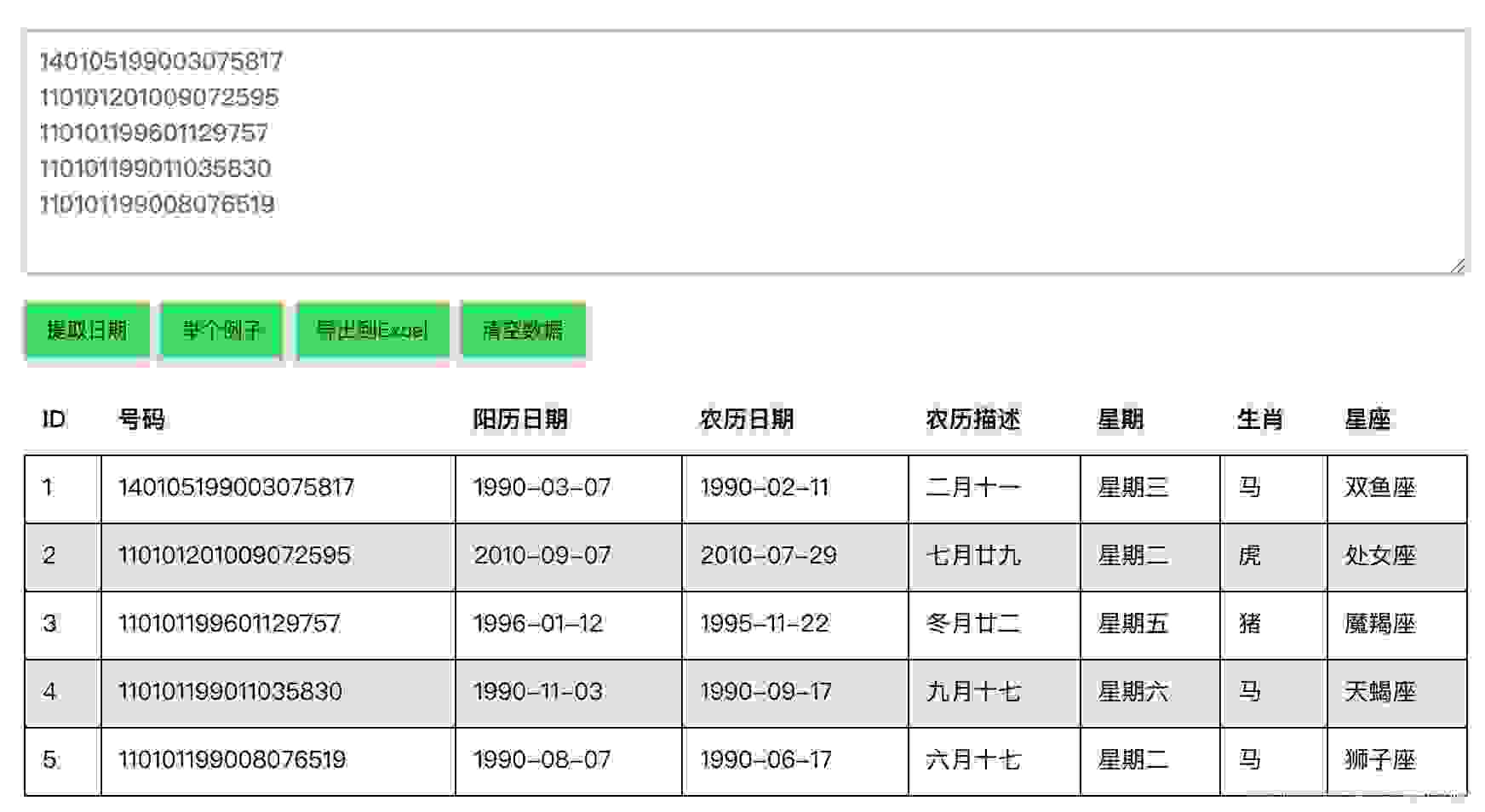
在线身份证号码提取生日工具
-
Online ID number extraction birthday tool
-
️野指针?悬空指针?️ 一文带你搞懂!
-
Field pointer? Dangling pointer? This article will help you understand!
-
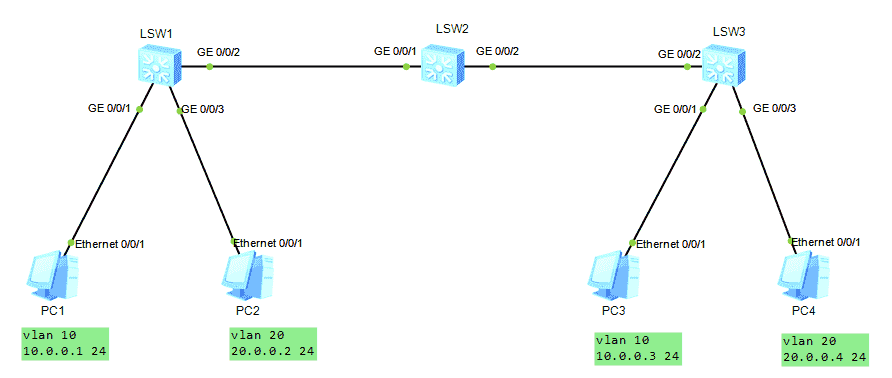
HCNA Routing&Switching之GVRP
-
GVRP of hcna Routing & Switching
-

Seq2Seq实现闲聊机器人
-
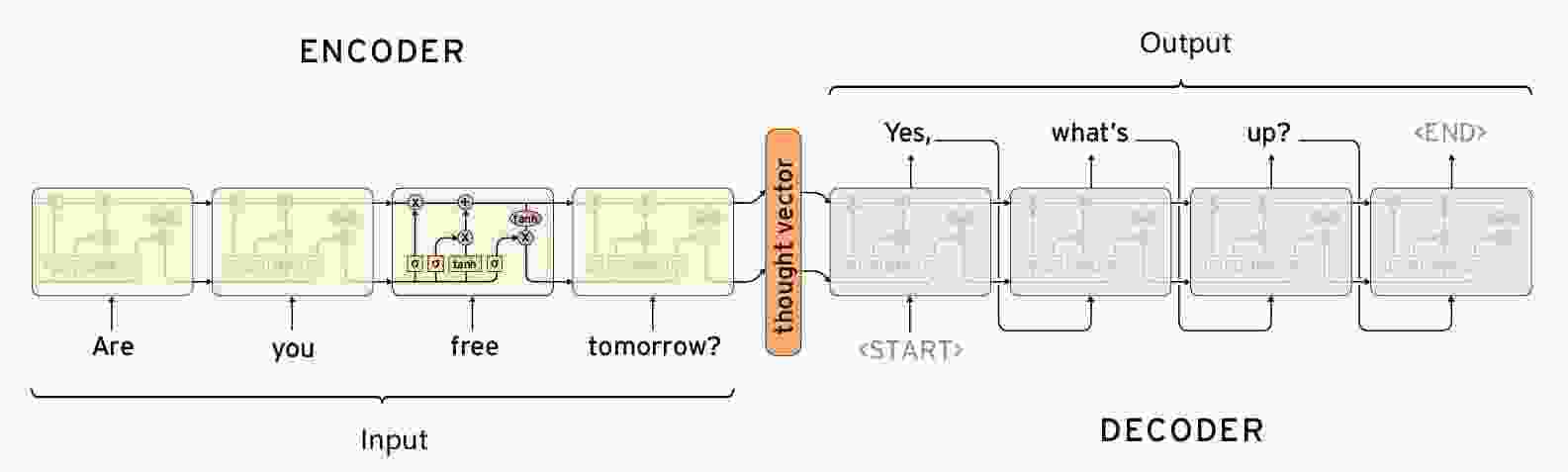
【闲聊机器人】seq2seq模型的原理
随机推荐
- LeetCode 91. 解码方法
- Seq2seq implements chat robot
- [chat robot] principle of seq2seq model
- Leetcode 91. Decoding method
- HCNA Routing&Switching之GVRP
- GVRP of hcna Routing & Switching
- HDU7016 Random Walk 2
- [Code+#1]Yazid 的新生舞会
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- HDU7016 Random Walk 2
- [code + 1] Yazid's freshman ball
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- Qt Creator 自动补齐变慢的解决
- HALCON 20.11:如何处理标定助手品质问题
- HALCON 20.11:标定助手使用注意事项
- Solution of QT creator's automatic replenishment slowing down
- Halcon 20.11: how to deal with the quality problem of calibration assistant
- Halcon 20.11: precautions for use of calibration assistant
- “十大科学技术问题”揭晓!|青年科学家50²论坛
- "Top ten scientific and technological issues" announced| Young scientists 50 ² forum
- 求反转链表
- Reverse linked list
- js的数据类型
- JS data type
- 记一次文件读写遇到的bug
- Remember the bug encountered in reading and writing a file
- 单例模式
- Singleton mode
- 在这个 N 多编程语言争霸的世界,C++ 究竟还有没有未来?
- In this world of N programming languages, is there a future for C + +?
- es6模板字符
- js Promise
- js 数组方法 回顾
- ES6 template characters
- js Promise
- JS array method review
- 【Golang】️走进 Go 语言️ 第一课 Hello World
- [golang] go into go language lesson 1 Hello World