当前位置:网站首页>基于 Flink SQL CDC 的实时数据同步方案
基于 Flink SQL CDC 的实时数据同步方案
2020-11-06 01:15:47 【InfoQ】
{"type":"doc","content":[{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"作者:伍翀 (云邪)"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"整理:陈政羽(Flink 社区志愿者)"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"Flink 1.11 引入了 Flink SQL CDC,CDC 能给我们数据和业务间能带来什么变化?本文由 Apache Flink PMC,阿里巴巴技术专家伍翀 (云邪)分享,内容将从传统的数据同步方案,基于 Flink CDC 同步的解决方案以及更多的应用场景和 CDC 未来开发规划等方面进行介绍和演示。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"1、传统数据同步方案"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"2、基于 Flink SQL CDC 的数据同步方案(Demo)"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"3、Flink SQL CDC 的更多应用场景"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"4、Flink SQL CDC 的未来规划"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"直播回顾:"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"link","attrs":{"href":"https://www.bilibili.com/video/BV1zt4y1D7kt/","title":""},"content":[{"type":"text","text":"https://www.bilibili.com/video/BV1zt4y1D7kt/"}]}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":2},"content":[{"type":"text","text":"传统的数据同步方案与 Flink SQL CDC 解决方案"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"业务系统经常会遇到需要更新数据到多个存储的需求。例如:一个订单系统刚刚开始只需要写入数据库即可完成业务使用。某天 BI 团队期望对数据库做全文索引,于是我们同时要写多一份数据到 ES 中,改造后一段时间,又有需求需要写入到 Redis 缓存中。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/37/37bd656e21eca39e3473101141e367c5.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"很明显这种模式是不可持续发展的,这种双写到各个数据存储系统中可能导致不可维护和扩展,数据一致性问题等,需要引入分布式事务,成本和复杂度也随之增加。我们可以通过 CDC(Change Data Capture)工具进行解除耦合,同步到下游需要同步的存储系统。通过这种方式提高系统的稳健性,也方便后续的维护。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/22/22f36f144b32026e8068f49466522b31.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":3},"content":[{"type":"text","text":"Flink SQL CDC 数据同步与原理解析"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"CDC 全称是 Change Data Capture ,它是一个比较广义的概念,只要能捕获变更的数据,我们都可以称为 CDC 。业界主要有基于查询的 CDC 和基于日志的 CDC ,可以从下面表格对比他们功能和差异点。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/dc/dc007990d5f22e16dc36d25a61e9f442.jpeg","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"经过以上对比,我们可以发现基于日志 CDC 有以下这几种优势:"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 能够捕获所有数据的变化,捕获完整的变更记录。在异地容灾,数据备份等场景中得到广泛应用,如果是基于查询的 CDC 有可能导致两次查询的中间一部分数据丢失"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 每次 DML 操作均有记录无需像查询 CDC 这样发起全表扫描进行过滤,拥有更高的效率和性能,具有低延迟,不增加数据库负载的优势"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 无需入侵业务,业务解耦,无需更改业务模型"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 捕获删除事件和捕获旧记录的状态,在查询 CDC 中,周期的查询无法感知中间数据是否删除"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/16/16bb1c899c42eb924ac16936f30063a6.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":3},"content":[{"type":"text","text":"基于日志的 CDC 方案介绍"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"从 ETL 的角度进行分析,一般采集的都是业务库数据,这里使用 MySQL 作为需要采集的数据库,通过 Debezium 把 MySQL Binlog 进行采集后发送至 Kafka 消息队列,然后对接一些实时计算引擎或者 APP 进行消费后把数据传输入 OLAP 系统或者其他存储介质。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"Flink 希望打通更多数据源,发挥完整的计算能力。我们生产中主要来源于业务日志和数据库日志,Flink 在业务日志的支持上已经非常完善,但是在数据库日志支持方面在 Flink 1.11 前还属于一片空白,这就是为什么要集成 CDC 的原因之一。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"Flink SQL 内部支持了完整的 changelog 机制,所以 Flink 对接 CDC 数据只需要把CDC 数据转换成 Flink 认识的数据,所以在 Flink 1.11 里面重构了 TableSource 接口,以便更好支持和集成 CDC。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/4c/4c3fe47c4c9c437eeab1ff817e84cdfd.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/3b/3b1c09ab7941fb18df97e7ebd2f3b0c7.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"重构后的 TableSource 输出的都是 RowData 数据结构,代表了一行的数据。在RowData 上面会有一个元数据的信息,我们称为 RowKind 。RowKind 里面包括了插入、更新前、更新后、删除,这样和数据库里面的 binlog 概念十分类似。通过 Debezium 采集的 JSON 格式,包含了旧数据和新数据行以及原数据信息,op 的 u表示是 update 更新操作标识符,ts_ms 表示同步的时间戳。因此,对接 Debezium JSON 的数据,其实就是将这种原始的 JSON 数据转换成 Flink 认识的 RowData。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":3},"content":[{"type":"text","text":"选择 Flink 作为 ETL 工具"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"当选择 Flink 作为 ETL 工具时,在数据同步场景,如下图同步结构:"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/90/901ca16246899d3df2110305af8499a3.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"通过 Debezium 订阅业务库 MySQL 的 Binlog 传输至 Kafka ,Flink 通过创建 Kafka 表指定 format 格式为 debezium-json ,然后通过 Flink 进行计算后或者直接插入到其他外部数据存储系统,例如图中的 Elasticsearch 和 PostgreSQL。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/e1/e11d15e04b580dd9b9e587fafcd77ba9.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"但是这个架构有个缺点,我们可以看到采集端组件过多导致维护繁杂,这时候就会想是否可以用 Flink SQL 直接对接 MySQL 的 binlog 数据呢,有没可以替代的方案呢?"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"答案是有的!经过改进后结构如下图:"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/92/92c1bedcdf9b678212048c04aeb10b26.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的 source 组件。目前也已开源,开源地址:"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"blockquote","content":[{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"link","attrs":{"href":"https://github.com/ververica/flink-cdc-connectors","title":""},"content":[{"type":"text","text":"https://github.com/ververica/flink-cdc-connectors"}]}]}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"flink-cdc-connectors 可以用来替换 Debezium+Kafka 的数据采集模块,从而实现 Flink SQL 采集+计算+传输(ETL)一体化,这样做的优点有以下:"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 开箱即用,简单易上手"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 减少维护的组件,简化实时链路,减轻部署成本"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 减小端到端延迟"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· Flink 自身支持 Exactly Once 的读取和计算"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 数据不落地,减少存储成本"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 支持全量和增量流式读取"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· binlog 采集位点可回溯*"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":2},"content":[{"type":"text","text":"基于 Flink SQL CDC 的数据同步方案实践"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"下面给大家带来 3 个关于 Flink SQL + CDC 在实际场景中使用较多的案例。在完成实验时候,你需要 Docker、MySQL、Elasticsearch 等组件,具体请参考每个案例参考文档。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":3},"content":[{"type":"text","text":"案例 1 : Flink SQL CDC + JDBC Connector"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"这个案例通过订阅我们订单表(事实表)数据,通过 Debezium 将 MySQL Binlog 发送至 Kafka,通过维表 Join 和 ETL 操作把结果输出至下游的 PG 数据库。具体可以参考 Flink 公众号文章:《Flink JDBC Connector:Flink 与数据库集成最佳实践》案例进行实践操作。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"link","attrs":{"href":"https://www.bilibili.com/video/BV1bp4y1q78d","title":""},"content":[{"type":"text","text":"https://www.bilibili.com/video/BV1bp4y1q78d"}]}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/99/99c39126acf4426a79acafd1f5f3c96d.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":3},"content":[{"type":"text","text":"案例 2 : CDC Streaming ETL"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"模拟电商公司的订单表和物流表,需要对订单数据进行统计分析,对于不同的信息需要进行关联后续形成订单的大宽表后,交给下游的业务方使用 ES 做数据分析,这个案例演示了如何只依赖 Flink 不依赖其他组件,借助 Flink 强大的计算能力实时把 Binlog 的数据流关联一次并同步至 ES 。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/2f/2f3ad35133725315ce1977a1edff666e.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"例如如下的这段 Flink SQL 代码就能完成实时同步 MySQL 中 orders 表的全量+增量数据的目的。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"codeblock","attrs":{"lang":""},"content":[{"type":"text","text":"CREATE TABLE orders (\n order_id INT,\n order_date TIMESTAMP(0),\n customer_name STRING,\n price DECIMAL(10, 5),\n product_id INT,\n order_status BOOLEAN\n) WITH (\n 'connector' = 'mysql-cdc',\n 'hostname' = 'localhost',\n 'port' = '3306',\n 'username' = 'root',\n 'password' = '123456',\n 'database-name' = 'mydb',\n 'table-name' = 'orders'\n);\n\nSELECT * FROM orders"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"为了让读者更好地上手和理解,我们还提供了 docker-compose 的测试环境,更详细的案例教程请参考下文的视频链接和文档链接。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"blockquote","content":[{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"视频链接:"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"link","attrs":{"href":"https://www.bilibili.com/video/BV1zt4y1D7kt","title":""},"content":[{"type":"text","text":"https://www.bilibili.com/video/BV1zt4y1D7kt"}]}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"文档教程:"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"link","attrs":{"href":"https://github.com/ververica/flink-cdc-connectors/wiki/","title":""},"content":[{"type":"text","text":"https://github.com/ververica/flink-cdc-connectors/wiki/"}]},{"type":"text","text":"中文教程"}]}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":3},"content":[{"type":"text","text":"案例 3 : Streaming Changes to Kafka"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"下面案例就是对 GMV 进行天级别的全站统计。包含插入/更新/删除,只有付款的订单才能计算进入 GMV ,观察 GMV 值的变化。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/53/533d676c9e779153d444add1360ce717.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"blockquote","content":[{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"视频链接:"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"link","attrs":{"href":"https://www.bilibili.com/video/BV1zt4y1D7kt","title":""},"content":[{"type":"text","text":"https://www.bilibili.com/video/BV1zt4y1D7kt"}]}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"文档教程:"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"link","attrs":{"href":"https://github.com/ververica/flink-cdc-connectors/wiki/","title":""},"content":[{"type":"text","text":"https://github.com/ververica/flink-cdc-connectors/wiki/"}]},{"type":"text","text":"中文教程"}]}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":2},"content":[{"type":"text","text":"Flink SQL CDC 的更多应用场景"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"Flink SQL CDC 不仅可以灵活地应用于实时数据同步场景中,还可以打通更多的场景提供给用户选择。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":3},"content":[{"type":"text","text":"Flink 在数据同步场景中的灵活定位"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 如果你已经有 Debezium/Canal + Kafka 的采集层 (E),可以使用 Flink 作为计算层 (T) 和传输层 (L)"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 也可以用 Flink 替代 Debezium/Canal ,由 Flink 直接同步变更数据到 Kafka,Flink 统一 ETL 流程"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 如果不需要 Kafka 数据缓存,可以由 Flink 直接同步变更数据到目的地,Flink 统一 ETL 流程"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":3},"content":[{"type":"text","text":"Flink SQL CDC : 打通更多场景"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 实时数据同步,数据备份,数据迁移,数仓构建"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"优势:丰富的上下游(E & L),强大的计算(T),易用的 API(SQL),流式计算低延迟"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 数据库之上的实时物化视图、流式数据分析"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 索引构建和实时维护"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 业务 cache 刷新"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 审计跟踪"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 微服务的解耦,读写分离"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 基于 CDC 的维表关联"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"下面介绍一下为何用 CDC 的维表关联会比基于查询的维表查询快。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","marks":[{"type":"strong"}],"text":"■ 基于查询的维表关联"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/72/72cfba125a85149e2b2356d93cb6f386.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"目前维表查询的方式主要是通过 Join 的方式,数据从消息队列进来后通过向数据库发起 IO 的请求,由数据库把结果返回后合并再输出到下游,但是这个过程无可避免的产生了 IO 和网络通信的消耗,导致吞吐量无法进一步提升,就算使用一些缓存机制,但是因为缓存更新不及时可能会导致精确性也没那么高。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","marks":[{"type":"strong"}],"text":"■ 基于 CDC 的维表关联"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"image","attrs":{"src":"https://static001.geekbang.org/infoq/b3/b3190b0323b6761c648e18b67263a741.png","alt":null,"title":"","style":[{"key":"width","value":"100%"},{"key":"bordertype","value":"none"}],"href":"","fromPaste":false,"pastePass":false}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"我们可以通过 CDC 把维表的数据导入到维表 Join 的状态里面,在这个 State 里面因为它是一个分布式的 State ,里面保存了 Database 里面实时的数据库维表镜像,当消息队列数据过来时候无需再次查询远程的数据库了,直接查询本地磁盘的 State ,避免了 IO 操作,实现了低延迟、高吞吐,更精准。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"Tips:目前此功能在 1.12 版本的规划中,具体进度请关注 FLIP-132 。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":2},"content":[{"type":"text","text":"未来规划"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· FLIP-132 :Temporal Table DDL(基于 CDC 的维表关联)"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· Upsert 数据输出到 Kafka"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 更多的 CDC formats 支持(debezium-avro, OGG, Maxwell)"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· 批模式支持处理 CDC 数据"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"· flink-cdc-connectors 支持更多数据库"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":2},"content":[{"type":"text","text":"总结"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"本文通过对比传统的数据同步方案与 Flink SQL CDC 方案分享了 Flink CDC 的优势,与此同时介绍了 CDC 分为日志型和查询型各自的实现原理。后续案例也演示了关于 Debezium 订阅 MySQL Binlog 的场景介绍,以及如何通过 flink-cdc-connectors 实现技术整合替代订阅组件。除此之外,还详细讲解了 Flink CDC 在数据同步、物化视图、多机房备份等的场景,并重点讲解了社区未来规划的基于 CDC 维表关联对比传统维表关联的优势以及 CDC 组件工作。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"希望通过这次分享,大家对 Flink SQL CDC 能有全新的认识和了解,在未来实际生产开发中,期望 Flink CDC 能带来更多开发的便捷和更丰富的使用场景。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"heading","attrs":{"align":null,"level":2},"content":[{"type":"text","text":"Q & A"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","marks":[{"type":"strong"}],"text":"1、GROUP BY 结果如何写到 Kafka ?"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"因为 group by 的结果是一个更新的结果,目前无法写入 append only 的消息队列中里面去。更新的结果写入 Kafka 中将在 1.12 版本中原生地支持。在 1.11 版本中,可以通过 flink-cdc-connectors 项目提供的 changelog-json format 来实现该功能,具体见文档。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"blockquote","content":[{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"文档链接:"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"link","attrs":{"href":"https://github.com/ververica/flink-cdc-connectors/wiki/Changelog-JSON-Format","title":""},"content":[{"type":"text","text":"https://github.com/ververica/flink-cdc-connectors/wiki/Changelog-JSON-Format"}]}]}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","marks":[{"type":"strong"}],"text":"2、CDC 是否需要保证顺序化消费?"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null},"content":[{"type":"text","text":"是的,数据同步到 kafka ,首先需要 kafka 在分区中保证有序,同一个 key 的变更数据需要打入到同一个 kafka 的分区里面。这样 flink 读取的时候才能保证顺序。"}]},{"type":"paragraph","attrs":{"indent":0,"number":0,"align":null,"origin":null}}]}
版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://xie.infoq.cn/article/8dae4d5478f751981905f2e8d?utm_source=rss&utm;_medium=article
边栏推荐
- C++ 数字、string和char*的转换
- C++学习——centos7上部署C++开发环境
- C++学习——一步步学会写Makefile
- C++学习——临时对象的产生与优化
- C++学习——对象的引用的用法
- C++编程经验(6):使用C++风格的类型转换
- Won the CKA + CKS certificate with the highest gold content in kubernetes in 31 days!
- C + + number, string and char * conversion
- C + + Learning -- capacity() and resize() in C + +
- C + + Learning -- about code performance optimization
猜你喜欢
-
C + + programming experience (6): using C + + style type conversion
-

Latest party and government work report ppt - Park ppt
-
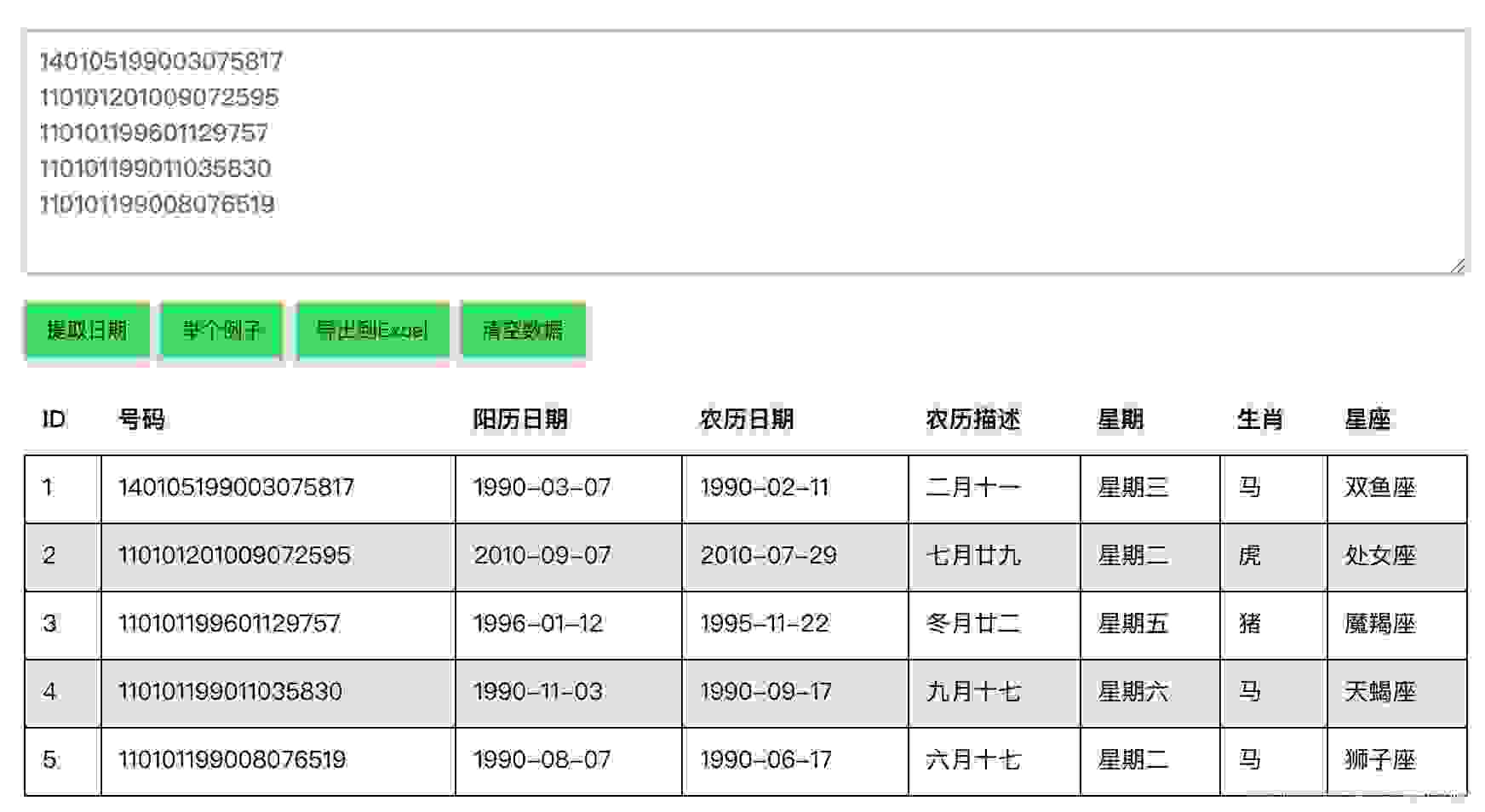
在线身份证号码提取生日工具
-
Online ID number extraction birthday tool
-
️野指针?悬空指针?️ 一文带你搞懂!
-
Field pointer? Dangling pointer? This article will help you understand!
-
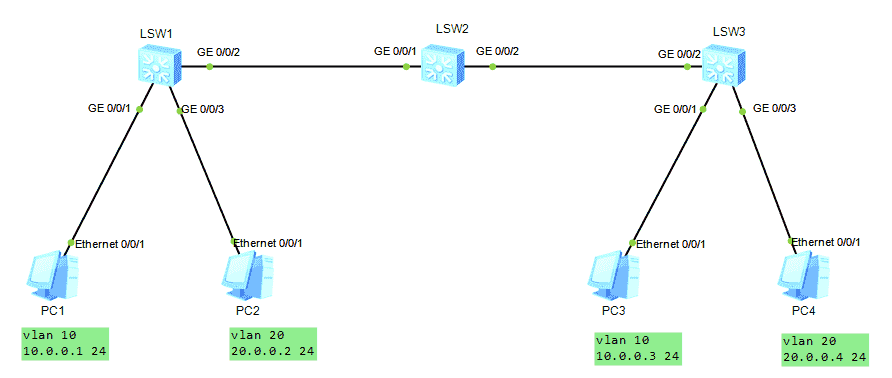
HCNA Routing&Switching之GVRP
-
GVRP of hcna Routing & Switching
-

Seq2Seq实现闲聊机器人
-
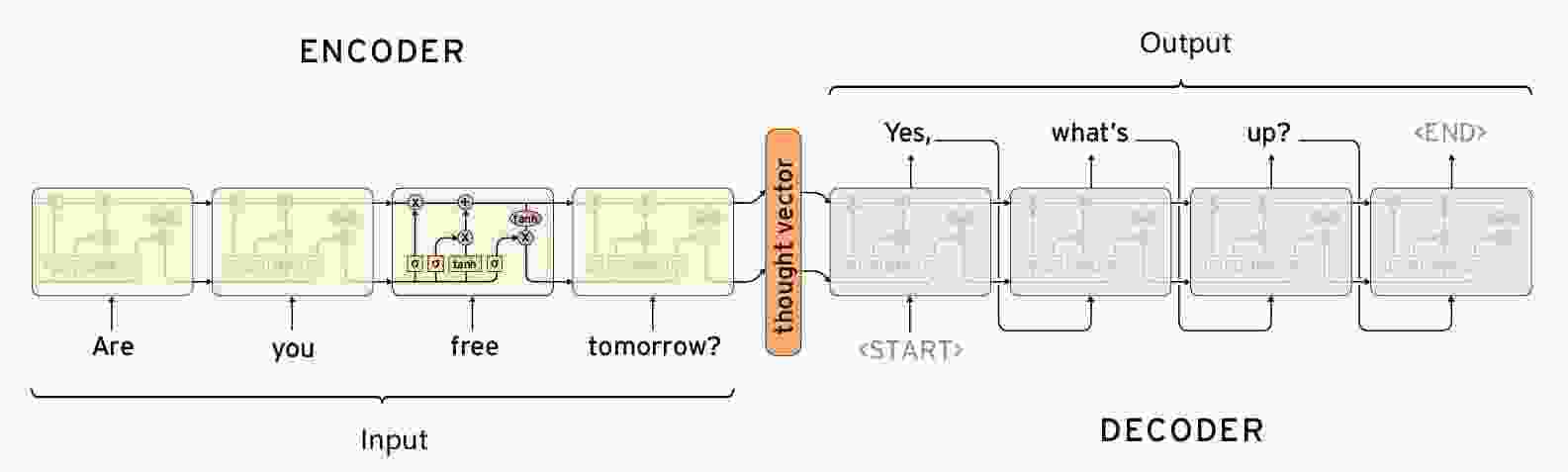
【闲聊机器人】seq2seq模型的原理
随机推荐
- LeetCode 91. 解码方法
- Seq2seq implements chat robot
- [chat robot] principle of seq2seq model
- Leetcode 91. Decoding method
- HCNA Routing&Switching之GVRP
- GVRP of hcna Routing & Switching
- HDU7016 Random Walk 2
- [Code+#1]Yazid 的新生舞会
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- HDU7016 Random Walk 2
- [code + 1] Yazid's freshman ball
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- Qt Creator 自动补齐变慢的解决
- HALCON 20.11:如何处理标定助手品质问题
- HALCON 20.11:标定助手使用注意事项
- Solution of QT creator's automatic replenishment slowing down
- Halcon 20.11: how to deal with the quality problem of calibration assistant
- Halcon 20.11: precautions for use of calibration assistant
- “十大科学技术问题”揭晓!|青年科学家50²论坛
- "Top ten scientific and technological issues" announced| Young scientists 50 ² forum
- 求反转链表
- Reverse linked list
- js的数据类型
- JS data type
- 记一次文件读写遇到的bug
- Remember the bug encountered in reading and writing a file
- 单例模式
- Singleton mode
- 在这个 N 多编程语言争霸的世界,C++ 究竟还有没有未来?
- In this world of N programming languages, is there a future for C + +?
- es6模板字符
- js Promise
- js 数组方法 回顾
- ES6 template characters
- js Promise
- JS array method review
- 【Golang】️走进 Go 语言️ 第一课 Hello World
- [golang] go into go language lesson 1 Hello World