当前位置:网站首页>通过深层神经网络生成音乐
通过深层神经网络生成音乐
2020-11-06 01:28:11 【人工智能遇见磐创】
作者|Ramya Vidiyala 编译|VK 来源|Towards Data Science
深度学习改善了我们生活的许多方面,无论是明显的还是微妙的。深度学习在电影推荐系统、垃圾邮件检测和计算机视觉等过程中起着关键作用。
尽管围绕深度学习作为黑匣子和训练难度的讨论仍在进行,但在医学、虚拟助理和电子商务等众多领域都存在着巨大的潜力。
在艺术和技术的交叉点,深度学习可以发挥作用。为了进一步探讨这一想法,在本文中,我们将研究通过深度学习过程生成机器学习音乐的过程,许多人认为这一领域超出了机器的范围(也是另一个激烈辩论的有趣领域!)。
目录
-
机器学习模型的音乐表现
-
音乐数据集
-
数据处理
-
模型选择
-
RNN
-
时间分布全连接层
-
状态
-
Dropout层
-
Softmax层
-
优化器
-
音乐生成
-
摘要
机器学习模型的音乐表现
我们将使用ABC音乐符号。ABC记谱法是一种简写的乐谱法,它使用字母a到G来表示音符,并使用其他元素来放置附加值。这些附加值包括音符长度、键和装饰。
这种形式的符号开始时是一种ASCII字符集代码,以便于在线音乐共享,为软件开发人员添加了一种新的简单的语言,便于使用。以下是ABC音乐符号。
乐谱记谱法第1部分中的行显示一个字母后跟一个冒号。这些表示曲调的各个方面,例如当文件中有多个曲调时的索引(X:)、标题(T:)、时间签名(M:)、默认音符长度(L:)、曲调类型(R:)和键(K:)。键名称后面代表旋律。
音乐数据集
在本文中,我们将使用诺丁汉音乐数据库ABC版上提供的开源数据。它包含了1000多首民谣曲调,其中绝大多数已被转换成ABC符号:http://abc.sourceforge.net/NMD/
数据处理
数据当前是基于字符的分类格式。在数据处理阶段,我们需要将数据转换成基于整数的数值格式,为神经网络的工作做好准备。
这里每个字符都映射到一个唯一的整数。这可以通过使用一行代码来实现。“text”变量是输入数据。
char_to_idx = { ch: i for (i, ch) in enumerate(sorted(list(set(text)))) }
为了训练模型,我们使用vocab将整个文本数据转换成数字格式。
T = np.asarray([char_to_idx[c] for c in text], dtype=np.int32)
机器学习音乐生成的模型选择
在传统的机器学习模型中,我们无法存储模型的前一阶段。然而,我们可以用循环神经网络(通常称为RNN)来存储之前的阶段。
RNN有一个重复模块,它从前一级获取输入,并将其输出作为下一级的输入。然而,RNN只能保留最近阶段的信息,因此我们的网络需要更多的内存来学习长期依赖关系。这就是长短期记忆网络(LSTMs)。
LSTMs是RNNs的一个特例,具有与RNNs相同的链状结构,但有不同的重复模块结构。
这里使用RNN是因为:
-
数据的长度不需要固定。对于每一个输入,数据长度可能会有所不同。
-
可以存储序列。
-
可以使用输入和输出序列长度的各种组合。
除了一般的RNN,我们还将通过添加一些调整来定制它以适应我们的用例。我们将使用“字符级RNN”。在字符RNNs中,输入、输出和转换输出都是以字符的形式出现的。
RNN
由于我们需要在每个时间戳上生成输出,所以我们将使用许多RNN。为了实现多个RNN,我们需要将参数“return_sequences”设置为true,以便在每个时间戳上生成每个字符。通过查看下面的图5,你可以更好地理解它。
在上图中,蓝色单位是输入单位,黄色单位是隐藏单位,绿色单位是输出单位。这是许多RNN的简单概述。为了更详细地了解RNN序列,这里有一个有用的资源:http://karpathy.github.io/2015/05/21/rnn-effectiveness/
时间分布全连接层
为了处理每个时间戳的输出,我们创建了一个时间分布的全连接层。为了实现这一点,我们在每个时间戳生成的输出之上创建了一个时间分布全连接层。
状态
通过将参数stateful设置为true,批处理的输出将作为输入传递给下一批。在组合了所有特征之后,我们的模型将如下面图6所示的概述。
模型体系结构的代码片段如下:
model = Sequential()
model.add(Embedding(vocab_size, 512, batch_input_shape=(BATCH_SIZE, SEQ_LENGTH)))
for i in range(3):
model.add(LSTM(256, return_sequences=True, stateful=True))
model.add(Dropout(0.2))
model.add(TimeDistributed(Dense(vocab_size)))
model.add(Activation('softmax'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
我强烈建议你使用层来提高性能。
Dropout层
Dropout层是一种正则化技术,在训练过程中,每次更新时将输入单元的一小部分归零,以防止过拟合。
Softmax层
音乐的生成是一个多类分类问题,每个类都是输入数据中唯一的字符。因此,我们在我们的模型上使用了一个softmax层,并将分类交叉熵作为一个损失函数。
这一层给出了每个类的概率。从概率列表中,我们选择概率最大的一个。
优化器
为了优化我们的模型,我们使用自适应矩估计,也称为Adam,因为它是RNN的一个很好的选择。
生成音乐
到目前为止,我们创建了一个RNN模型,并根据我们的输入数据对其进行训练。该模型在训练阶段学习输入数据的模式。我们把这个模型称为“训练模型”。
在训练模型中使用的输入大小是批大小。对于通过机器学习产生的音乐来说,输入大小是单个字符。所以我们创建了一个新的模型,它和""训练模型""相似,但是输入一个字符的大小是(1,1)。在这个新模型中,我们从训练模型中加载权重来复制训练模型的特征。
model2 = Sequential()
model2.add(Embedding(vocab_size, 512, batch_input_shape=(1,1)))
for i in range(3):
model2.add(LSTM(256, return_sequences=True, stateful=True))
model2.add(Dropout(0.2))
model2.add(TimeDistributed(Dense(vocab_size)))
model2.add(Activation(‘softmax’))
我们将训练好的模型的权重加载到新模型中。这可以通过使用一行代码来实现。
model2.load_weights(os.path.join(MODEL_DIR,‘weights.100.h5’.format(epoch)))
model2.summary()
在音乐生成过程中,从唯一的字符集中随机选择第一个字符,使用先前生成的字符生成下一个字符,依此类推。有了这个结构,我们就产生了音乐。
下面是帮助我们实现这一点的代码片段。
sampled = []
for i in range(1024):
batch = np.zeros((1, 1))
if sampled:
batch[0, 0] = sampled[-1]
else:
batch[0, 0] = np.random.randint(vocab_size)
result = model2.predict_on_batch(batch).ravel()
sample = np.random.choice(range(vocab_size), p=result)
sampled.append(sample)
print("sampled")
print(sampled)
print(''.join(idx_to_char[c] for c in sampled))
以下是一些生成的音乐片段:
我们使用被称为LSTMs的机器学习神经网络生成这些令人愉快的音乐样本。每一个片段都不同,但与训练数据相似。这些旋律可用于多种用途:
-
通过灵感提升艺术家的创造力
-
作为开发新思想的生产力工具
-
作为艺术家作品的附加曲调
-
完成未完成的工作
-
作为一首独立的音乐
但是,这个模型还有待改进。我们的训练资料只有一种乐器,钢琴。我们可以增强训练数据的一种方法是添加来自多种乐器的音乐。另一种方法是增加音乐的体裁、节奏和节奏特征。
目前,我们的模式产生了一些假音符,音乐也不例外。我们可以通过增加训练数据集来减少这些错误并提高音乐质量。
总结
在这篇文章中,我们研究了如何处理与神经网络一起使用的音乐,深度学习模型如RNN和LSTMs的工作原理,我们还探讨了如何调整模型可以产生音乐。我们可以将这些概念应用到任何其他系统中,在这些系统中,我们可以生成其他形式的艺术,包括生成风景画或人像。
谢谢你的阅读!如果你想亲自体验这个定制数据集,可以在这里下载带注释的数据,并在Github上查看我的代码:https://github.com/RamyaVidiyala/Generate-Music-Using-Neural-Networks
原文链接:https://towardsdatascience.com/music-generation-through-deep-neural-networks-21d7bd81496e
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/
版权声明
本文为[人工智能遇见磐创]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4253699/blog/4697472
边栏推荐
- C++ 数字、string和char*的转换
- C++学习——centos7上部署C++开发环境
- C++学习——一步步学会写Makefile
- C++学习——临时对象的产生与优化
- C++学习——对象的引用的用法
- C++编程经验(6):使用C++风格的类型转换
- Won the CKA + CKS certificate with the highest gold content in kubernetes in 31 days!
- C + + number, string and char * conversion
- C + + Learning -- capacity() and resize() in C + +
- C + + Learning -- about code performance optimization
猜你喜欢
-
C + + programming experience (6): using C + + style type conversion
-

Latest party and government work report ppt - Park ppt
-
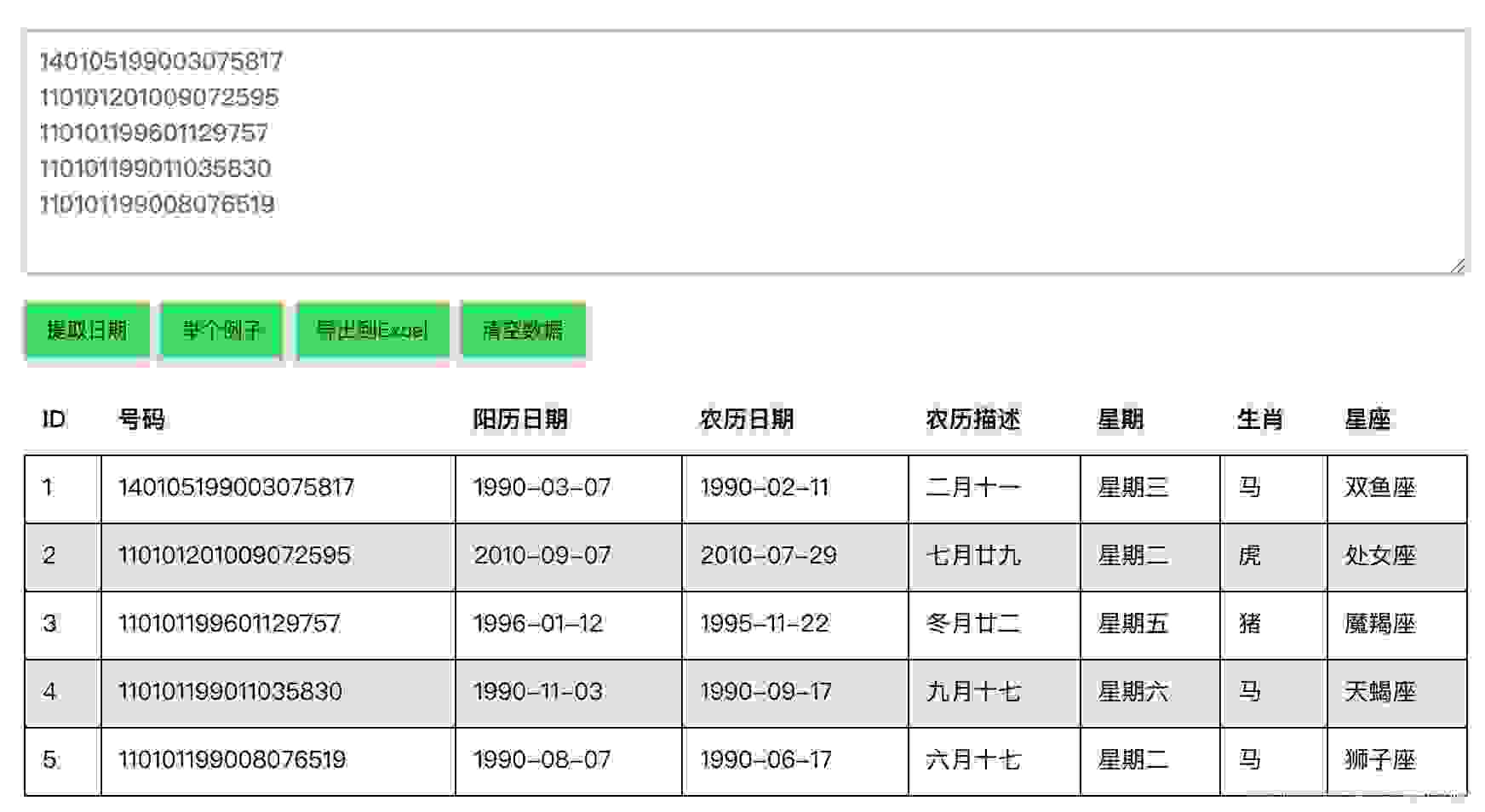
在线身份证号码提取生日工具
-
Online ID number extraction birthday tool
-
️野指针?悬空指针?️ 一文带你搞懂!
-
Field pointer? Dangling pointer? This article will help you understand!
-
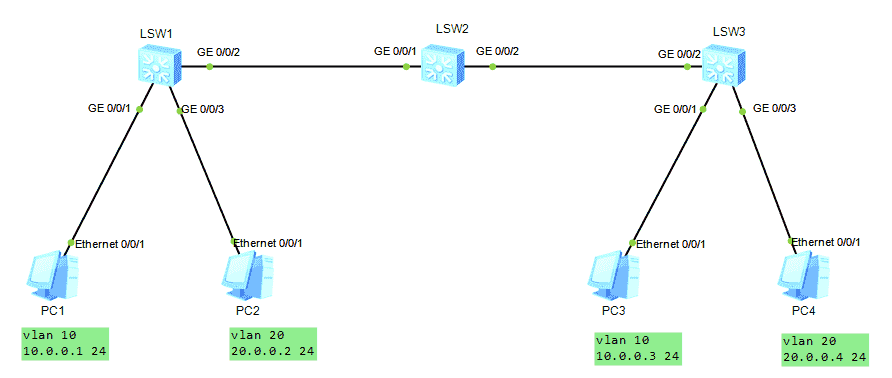
HCNA Routing&Switching之GVRP
-
GVRP of hcna Routing & Switching
-

Seq2Seq实现闲聊机器人
-
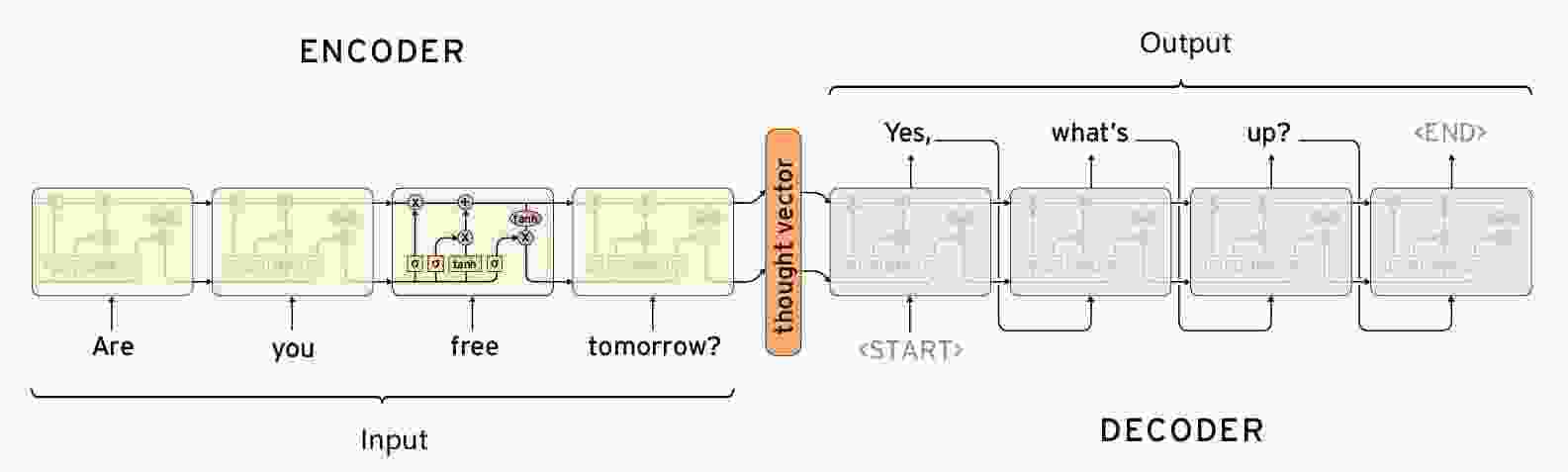
【闲聊机器人】seq2seq模型的原理
随机推荐
- LeetCode 91. 解码方法
- Seq2seq implements chat robot
- [chat robot] principle of seq2seq model
- Leetcode 91. Decoding method
- HCNA Routing&Switching之GVRP
- GVRP of hcna Routing & Switching
- HDU7016 Random Walk 2
- [Code+#1]Yazid 的新生舞会
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- HDU7016 Random Walk 2
- [code + 1] Yazid's freshman ball
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- Qt Creator 自动补齐变慢的解决
- HALCON 20.11:如何处理标定助手品质问题
- HALCON 20.11:标定助手使用注意事项
- Solution of QT creator's automatic replenishment slowing down
- Halcon 20.11: how to deal with the quality problem of calibration assistant
- Halcon 20.11: precautions for use of calibration assistant
- “十大科学技术问题”揭晓!|青年科学家50²论坛
- "Top ten scientific and technological issues" announced| Young scientists 50 ² forum
- 求反转链表
- Reverse linked list
- js的数据类型
- JS data type
- 记一次文件读写遇到的bug
- Remember the bug encountered in reading and writing a file
- 单例模式
- Singleton mode
- 在这个 N 多编程语言争霸的世界,C++ 究竟还有没有未来?
- In this world of N programming languages, is there a future for C + +?
- es6模板字符
- js Promise
- js 数组方法 回顾
- ES6 template characters
- js Promise
- JS array method review
- 【Golang】️走进 Go 语言️ 第一课 Hello World
- [golang] go into go language lesson 1 Hello World