当前位置:网站首页>基于SVM的异常检测方法
基于SVM的异常检测方法
2020-11-06 01:14:25 【人工智能遇见磐创】
作者|Mahbubul Alam 编译|VK 来源|Towards Data Science
单类支持向量机简介
作为机器学习方面的专家或新手,你可能听说过支持向量机(SVM)——一种经常被引用和用于分类问题的有监督的机器学习算法。
支持向量机使用多维空间中的超平面来分离一类观测值和另一类观测值。当然,支持向量机被用来解决多类分类问题。
然而,支持向量机也越来越多地应用于一类问题,即所有的数据都属于一个类。在这种情况下,算法被训练成学习什么是“正常的”,这样当一个新的数据被显示时,算法可以识别它是否应该属于正常的。如果没有,新数据将被标记为异常或异常。要了解更多关于单类支持向量机的信息,请查看Roemer Vlasveld的这篇长篇文章:http://rvlasveld.github.io/blog/2013/07/12/introduction-to-one-class-support-vector-machines/
最后要提到的是,如果你熟悉sklearn库,你会注意到有一种算法专门为所谓的“新颖性检测”而设计。它的工作方式与我刚才在使用单类支持向量机的异常检测中描述的方法类似。在我看来,只是上下文决定了是否将其称为新颖性检测或异常值检测或诸如此类的名称。
下面是Python编程语言中单类支持向量机的简单演示。请注意,我交替使用离群值和异常值。
步骤1:导入库
对于这个演示,我们需要三个核心库-用于数据争拗的python和numpy,用于模型构建sklearn和可视化matlotlib。
# 导入库
import pandas as pd
from sklearn.svm import OneClassSVM
import matplotlib.pyplot as plt
from numpy import where
步骤2:准备数据
我使用的是来自在线资源的著名的Iris数据集,因此你可以练习使用,而不必担心如何从何处获取数据。
# 导入数据
data = pd.read_csv("https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv")
# 输入数据
df = data[["sepal_length", "sepal_width"]]
步骤3:模型
与其他分类算法中的超参数调整不同,单类支持向量机使用nu作为超参数,用来定义哪些部分的数据应该被分类为异常值。nu=0.03表示算法将3%的数据指定为异常值。
# 模型参数
model = OneClassSVM(kernel = 'rbf', gamma = 0.001, nu = 0.03).fit(df)
步骤4:预测
预测的数据集将有1或-1值,其中-1值是算法检测到的异常值。
# 预测
y_pred = model.predict(df)
y_pred
步骤5:过滤异常
# 过滤异常值索引
outlier_index = where(y_pred == -1)
# 过滤异常值
outlier_values = df.iloc[outlier_index]
outlier_values
步骤6:可视化异常
# 可视化输出
plt.scatter(data["sepal_length"], df["sepal_width"])
plt.scatter(outlier_values["sepal_length"], outlier_values["sepal_width"], c = "r")
红色的数据点是离群值
总结
在本文中,我想对一类支持向量机(One-classsvm)做一个简单的介绍,这是一种用于欺诈/异常/异常检测的机器学习算法。
我展示了一些构建直觉的简单步骤,但是当然,一个真实的实现需要更多的实验来找出在特定的环境和行业中什么是有效的,什么是不起作用的。
原文链接:https://towardsdatascience.com/support-vector-machine-svm-for-anomaly-detection-73a8d676c331
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/
版权声明
本文为[人工智能遇见磐创]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4253699/blog/4701575
边栏推荐
- C++ 数字、string和char*的转换
- C++学习——centos7上部署C++开发环境
- C++学习——一步步学会写Makefile
- C++学习——临时对象的产生与优化
- C++学习——对象的引用的用法
- C++编程经验(6):使用C++风格的类型转换
- Won the CKA + CKS certificate with the highest gold content in kubernetes in 31 days!
- C + + number, string and char * conversion
- C + + Learning -- capacity() and resize() in C + +
- C + + Learning -- about code performance optimization
猜你喜欢
-
C + + programming experience (6): using C + + style type conversion
-

Latest party and government work report ppt - Park ppt
-
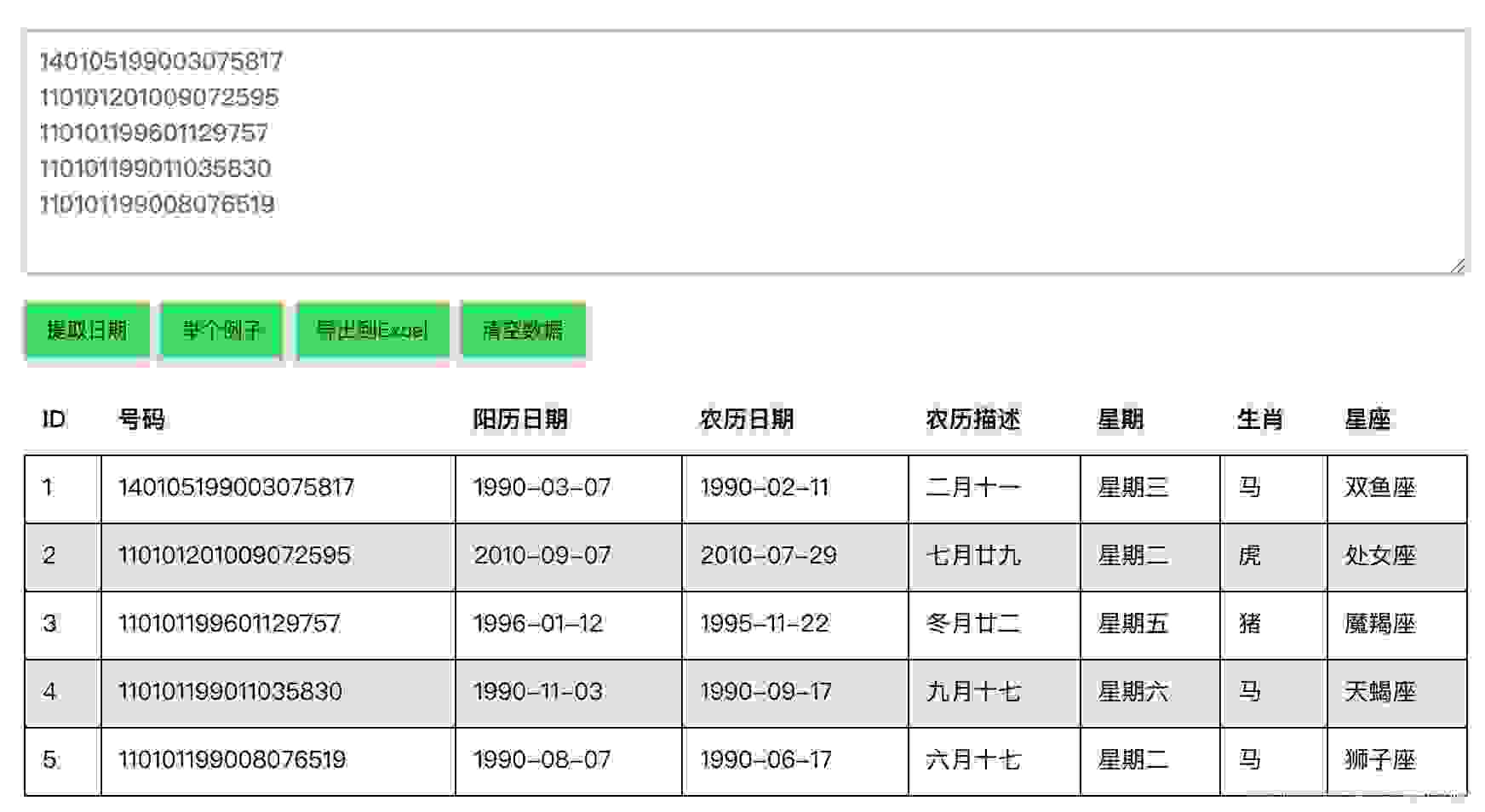
在线身份证号码提取生日工具
-
Online ID number extraction birthday tool
-
️野指针?悬空指针?️ 一文带你搞懂!
-
Field pointer? Dangling pointer? This article will help you understand!
-
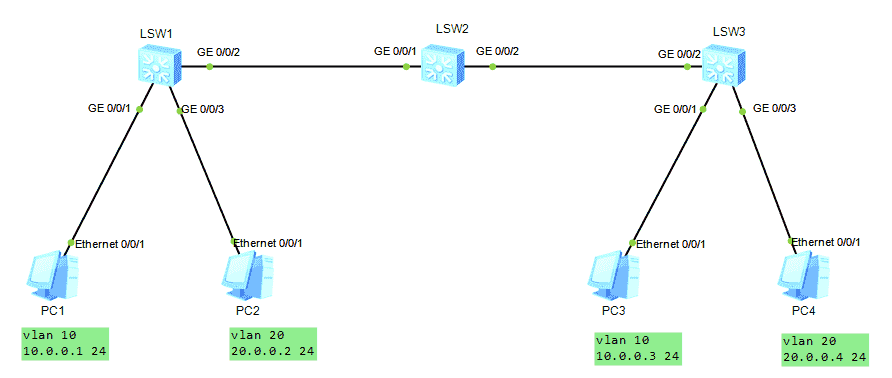
HCNA Routing&Switching之GVRP
-
GVRP of hcna Routing & Switching
-

Seq2Seq实现闲聊机器人
-
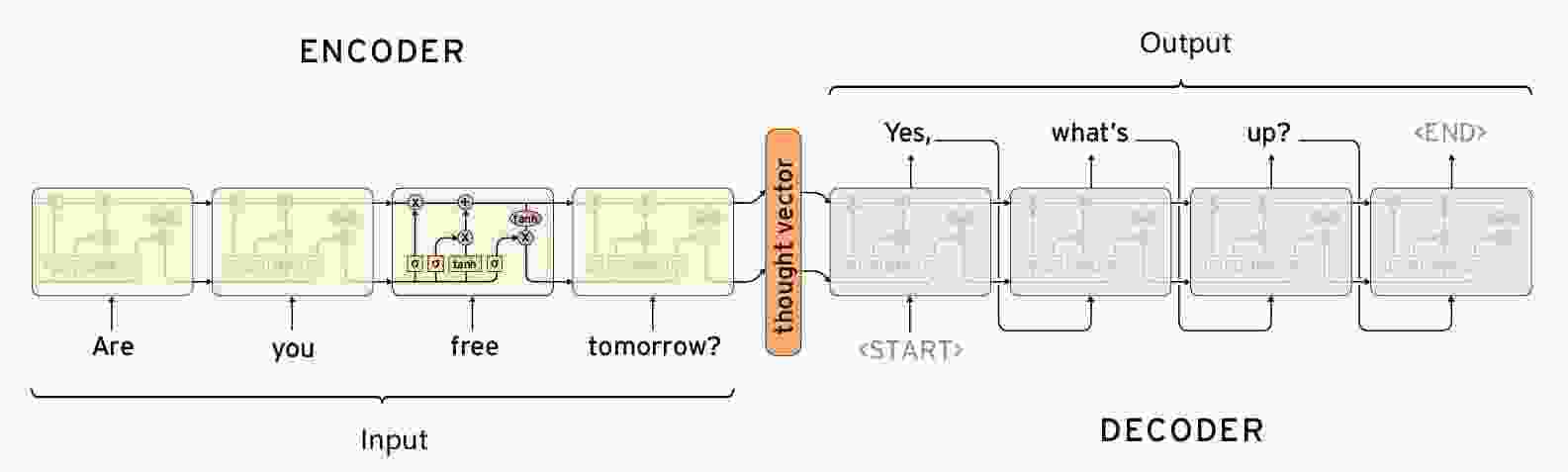
【闲聊机器人】seq2seq模型的原理
随机推荐
- LeetCode 91. 解码方法
- Seq2seq implements chat robot
- [chat robot] principle of seq2seq model
- Leetcode 91. Decoding method
- HCNA Routing&Switching之GVRP
- GVRP of hcna Routing & Switching
- HDU7016 Random Walk 2
- [Code+#1]Yazid 的新生舞会
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- HDU7016 Random Walk 2
- [code + 1] Yazid's freshman ball
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- Qt Creator 自动补齐变慢的解决
- HALCON 20.11:如何处理标定助手品质问题
- HALCON 20.11:标定助手使用注意事项
- Solution of QT creator's automatic replenishment slowing down
- Halcon 20.11: how to deal with the quality problem of calibration assistant
- Halcon 20.11: precautions for use of calibration assistant
- “十大科学技术问题”揭晓!|青年科学家50²论坛
- "Top ten scientific and technological issues" announced| Young scientists 50 ² forum
- 求反转链表
- Reverse linked list
- js的数据类型
- JS data type
- 记一次文件读写遇到的bug
- Remember the bug encountered in reading and writing a file
- 单例模式
- Singleton mode
- 在这个 N 多编程语言争霸的世界,C++ 究竟还有没有未来?
- In this world of N programming languages, is there a future for C + +?
- es6模板字符
- js Promise
- js 数组方法 回顾
- ES6 template characters
- js Promise
- JS array method review
- 【Golang】️走进 Go 语言️ 第一课 Hello World
- [golang] go into go language lesson 1 Hello World