当前位置:网站首页>自然语言处理-搜索中常用的bm25
自然语言处理-搜索中常用的bm25
2020-11-06 01:22:17 【IT界的小小小学生】
BM25算法是一种常见用来做相关度打分的公式,思路比较简单,主要就是计算一个query里面所有词和文档的相关度,然后在把分数做累加操作,而每个词的相关度分数主要还是受到tf/idf的影响。
关于Bim
BIM(二元假设模型)对于单词特征,只考虑单词是否在doc中出现过,并没有考虑单词本身的相关特征,BM25在BIM的基础上引入单词在查询中的权值,单词在doc中的权值,以及一些经验参数,所以BM25在实际应用中效果要远远好于BIM模型。
具体的bm25
bm25算法是常见的用来计算query和文章相关度的相似度的。其实这个算法的原理很简单,就是将需要计算的query分词成w1,w2,…,wn,然后求出每一个词和文章的相关度,最后将这些相关度进行累加,最终就可以的得到文本相似度计算结果。
首先Wi表示第i个词的权重,这里我们一般会使用TF-IDF算法来计算词语的权重这个公式第二项R(qi,d)表示我们查询query中的每一个词和文章d的相关度,这一项就涉及到复杂的运算,我们慢慢来看。一般来说Wi的计算我们一般用逆项文本频率IDF的计算公式:
在这个公式中,N表示文档的总数,n(qi)表示包含这个词的文章数,为了避免对数里面分母项等于0,我们给分子分母同时加上0.5,这个0.5被称作调教系数,所以当n(qi)越小的时候IDF值就越大,表示词的权重就越大。
来举个栗子:“bm25”这个词只在很少一部分的文章中出现,n(qi)就会很小,那么“bm25”的IDF值就很大;“我们”,“是”,“的”这样的词,基本上在每一篇文章中都会出现,那么n(qi)就很接近N,所以IDF值就很接近于0,
接着我们来看公式中的第二项R(qi,d),接着来看看第二项的计算公式:
在这个公式中,一般来说,k1、k2和b都是调节因子,k1=1、k2=1、b = 0.75,qfi表示qi在查询query中出现的频率,fi表示qi在文档d中出现的频率,因为在一般的情况下,qi在查询query中只会出现一次,因此把qfi=1和k2=1代入上述公式中,后面一项就等于1,最终可以得到:
我们再来看看K,在这里其实K的值也是一个公式的缩写,我们把K展开来看:
在K的展开式中dl表示文档的长度,avg(dl)表示文档的平均长度,b是前面提到的调节因子,从公式中可以看出在文章长度比平均文章长度固定的情况下,调节因子b越大,文章长度占有的影响权重就越大,反之则越小。在调节因子b固定的时候,当文章的长度比文章的平均长度越大,则K越大,R(qi,d)就越小。我们把K的展开式带入到bm25计算公式中去:
以上就是bm25算法的流程了。
以下是实现过程:
版权声明
本文为[IT界的小小小学生]所创,转载请带上原文链接,感谢
https://vip01.blog.csdn.net/article/details/103206166
边栏推荐
- C++ 数字、string和char*的转换
- C++学习——centos7上部署C++开发环境
- C++学习——一步步学会写Makefile
- C++学习——临时对象的产生与优化
- C++学习——对象的引用的用法
- C++编程经验(6):使用C++风格的类型转换
- Won the CKA + CKS certificate with the highest gold content in kubernetes in 31 days!
- C + + number, string and char * conversion
- C + + Learning -- capacity() and resize() in C + +
- C + + Learning -- about code performance optimization
猜你喜欢
-
C + + programming experience (6): using C + + style type conversion
-

Latest party and government work report ppt - Park ppt
-
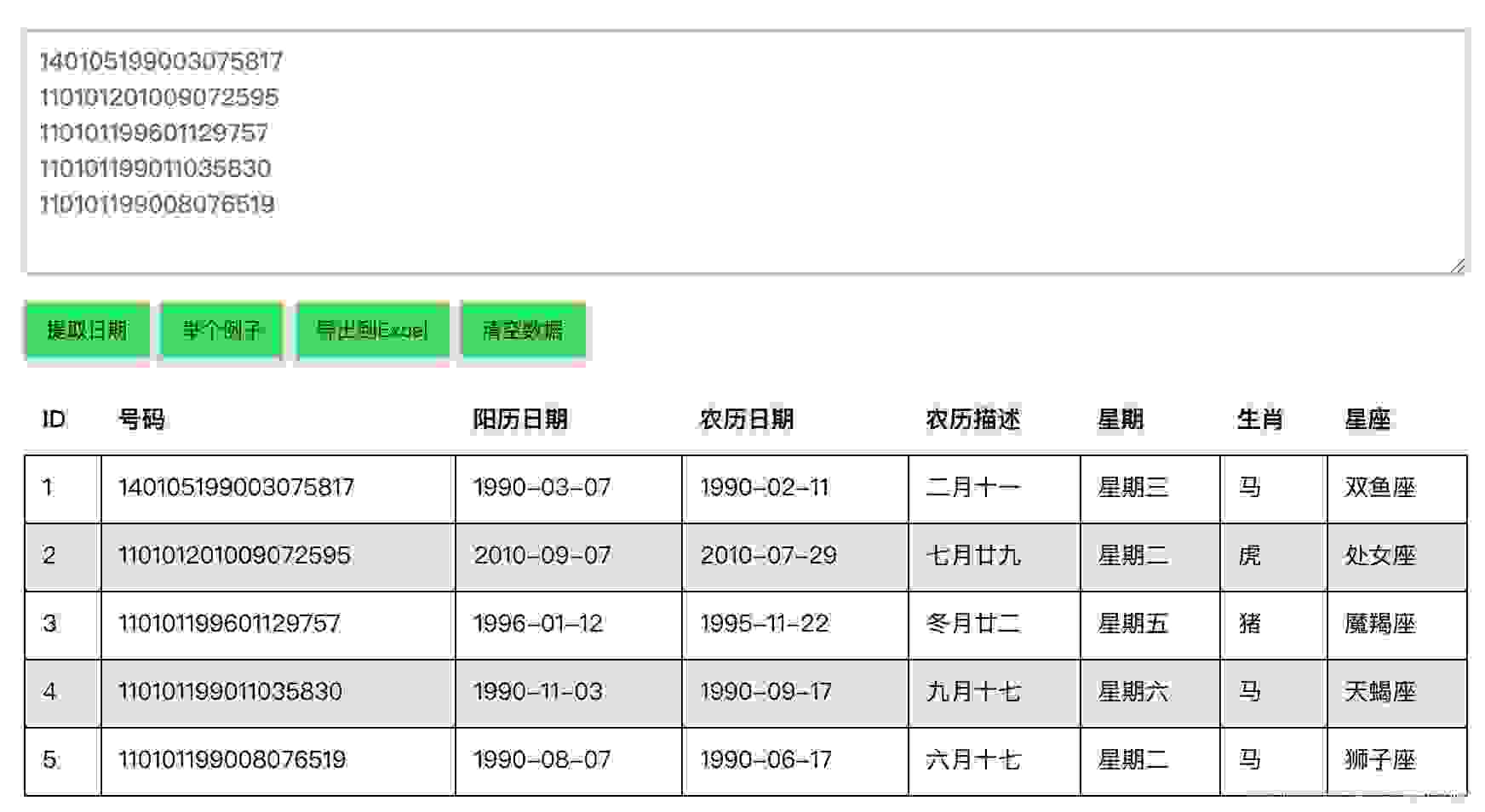
在线身份证号码提取生日工具
-
Online ID number extraction birthday tool
-
️野指针?悬空指针?️ 一文带你搞懂!
-
Field pointer? Dangling pointer? This article will help you understand!
-
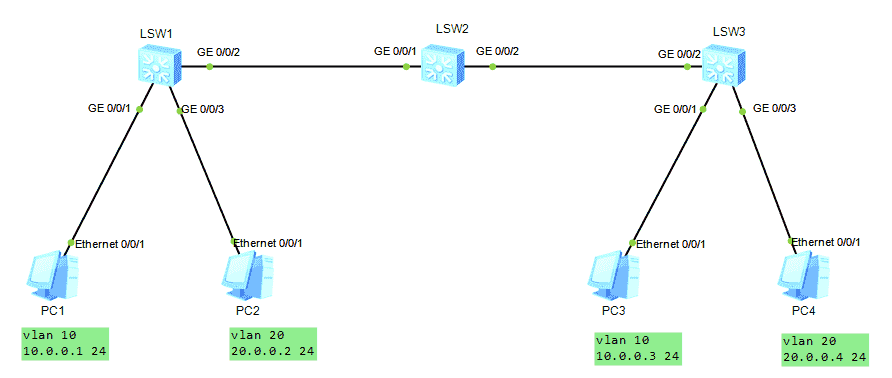
HCNA Routing&Switching之GVRP
-
GVRP of hcna Routing & Switching
-

Seq2Seq实现闲聊机器人
-
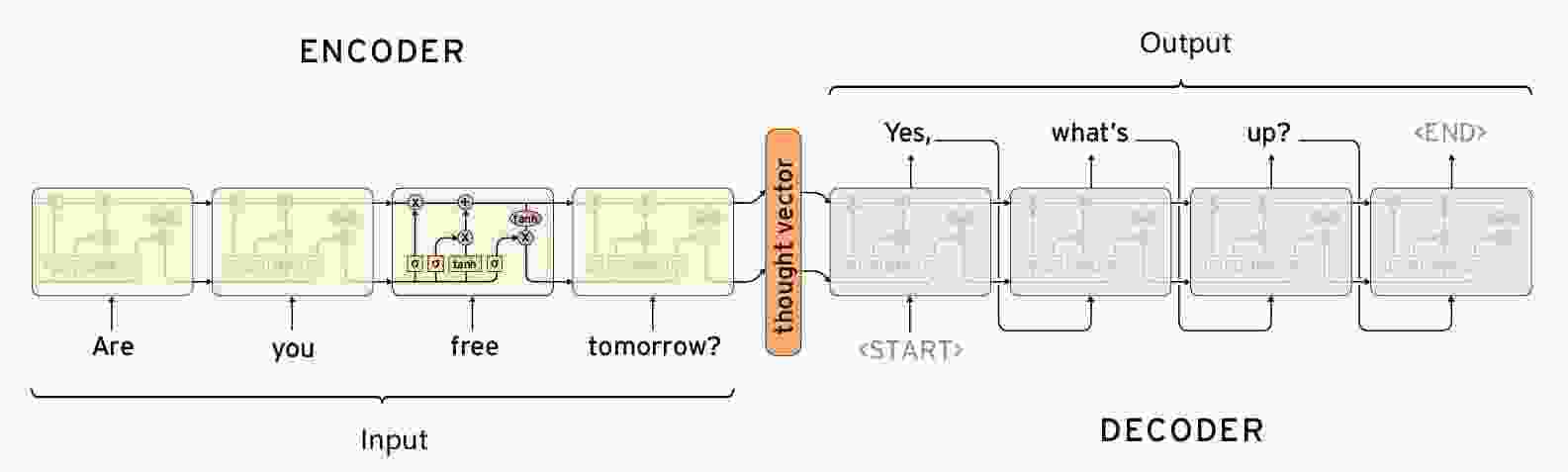
【闲聊机器人】seq2seq模型的原理
随机推荐
- LeetCode 91. 解码方法
- Seq2seq implements chat robot
- [chat robot] principle of seq2seq model
- Leetcode 91. Decoding method
- HCNA Routing&Switching之GVRP
- GVRP of hcna Routing & Switching
- HDU7016 Random Walk 2
- [Code+#1]Yazid 的新生舞会
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- HDU7016 Random Walk 2
- [code + 1] Yazid's freshman ball
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- Qt Creator 自动补齐变慢的解决
- HALCON 20.11:如何处理标定助手品质问题
- HALCON 20.11:标定助手使用注意事项
- Solution of QT creator's automatic replenishment slowing down
- Halcon 20.11: how to deal with the quality problem of calibration assistant
- Halcon 20.11: precautions for use of calibration assistant
- “十大科学技术问题”揭晓!|青年科学家50²论坛
- "Top ten scientific and technological issues" announced| Young scientists 50 ² forum
- 求反转链表
- Reverse linked list
- js的数据类型
- JS data type
- 记一次文件读写遇到的bug
- Remember the bug encountered in reading and writing a file
- 单例模式
- Singleton mode
- 在这个 N 多编程语言争霸的世界,C++ 究竟还有没有未来?
- In this world of N programming languages, is there a future for C + +?
- es6模板字符
- js Promise
- js 数组方法 回顾
- ES6 template characters
- js Promise
- JS array method review
- 【Golang】️走进 Go 语言️ 第一课 Hello World
- [golang] go into go language lesson 1 Hello World