当前位置:网站首页>ETCD核心機制解析
ETCD核心機制解析
2020-11-06 01:23:14 【itread01】
ETCD整體機制
etcd 是一個分散式的、可靠的 key-value 儲存系統,它適用於儲存分散式系統中的關鍵資料。
etcd 叢集中多個節點之間通過Raft演算法完成分散式一致性協同,演算法會選舉出一個主節點作為 leader,由 leader 負責資料的同步與分發。當 leader 出現故障後系統會自動地重新選取另一個節點成為 leader,並重新完成資料的同步。
etcd叢集實現高可用主要是基於quorum機制,即:叢集中半數以上的節點可用時,叢集才可繼續提供服務,quorum機制在分散式一致性演算法中應用非常廣泛,此處不再詳細闡述。
raft資料更新和etcd呼叫是基於兩階段機制:
第一階段 leader記錄log (uncommited);日誌複製到follower;follower響應,操作成功,響應客戶端;呼叫者呼叫leader,leader會將kv資料儲存在日誌中,並利用實時演算法raft進行復制
第二階段 leader commit;通知follower;當複製給了N+1個節點後,本地提交,返回給客戶端,最後leader非同步通知follower完成通知
ETCD核心API分析
etcd提供的api主要有kv相關、lease相關及watch,檢視其原始碼可知:
kv相關介面:
type KV interface {
// Put puts a key-value pair into etcd.
// Note that key,value can be plain bytes array and string is
// an immutable representation of that bytes array.
// To get a string of bytes, do string([]byte{0x10, 0x20}).
Put(ctx context.Context, key, val string, opts ...OpOption) (*PutResponse, error)
// Get retrieves keys.
// By default, Get will return the value for "key", if any.
// When passed WithRange(end), Get will return the keys in the range [key, end).
// When passed WithFromKey(), Get returns keys greater than or equal to key.
// When passed WithRev(rev) with rev > 0, Get retrieves keys at the given revision;
// if the required revision is compacted, the request will fail with ErrCompacted .
// When passed WithLimit(limit), the number of returned keys is bounded by limit.
// When passed WithSort(), the keys will be sorted.
Get(ctx context.Context, key string, opts ...OpOption) (*GetResponse, error)
// Delete deletes a key, or optionally using WithRange(end), [key, end).
Delete(ctx context.Context, key string, opts ...OpOption) (*DeleteResponse, error)
// Compact compacts etcd KV history before the given rev.
Compact(ctx context.Context, rev int64, opts ...CompactOption) (*CompactResponse, error)
// Txn creates a transaction.
Txn(ctx context.Context) Txn
}
主要有Put、Get、Delete、Compact、Do和Txn方法;Put用於向etcd叢集中寫入訊息,以key value的形式儲存;Get可以根據key檢視其對應儲存在etcd中的資料;Delete通過刪除key來刪除etcd中的資料;Compact 方法用於壓縮 etcd 鍵值對儲存中的事件歷史,避免事件歷史無限制的持續增長;Txn 方法在單個事務中處理多個請求,etcd事務模式為:
if compare
then op
else op
commit
lease相關介面:
type Lease interface {
// Grant creates a new lease.
Grant(ctx context.Context, ttl int64) (*LeaseGrantResponse, error)
// Revoke revokes the given lease.
Revoke(ctx context.Context, id LeaseID) (*LeaseRevokeResponse, error)
// TimeToLive retrieves the lease information of the given lease ID.
TimeToLive(ctx context.Context, id LeaseID, opts ...LeaseOption) (*LeaseTimeToLiveResponse, error)
// Leases retrieves all leases.
Leases(ctx context.Context) (*LeaseLeasesResponse, error)
// KeepAlive keeps the given lease alive forever. If the keepalive response
// posted to the channel is not consumed immediately, the lease client will
// continue sending keep alive requests to the etcd server at least every
// second until latest response is consumed.
//
// The returned "LeaseKeepAliveResponse" channel closes if underlying keep
// alive stream is interrupted in some way the client cannot handle itself;
// given context "ctx" is canceled or timed out. "LeaseKeepAliveResponse"
// from this closed channel is nil.
//
// If client keep alive loop halts with an unexpected error (e.g. "etcdserver:
// no leader") or canceled by the caller (e.g. context.Canceled), the error
// is returned. Otherwise, it retries.
//
// TODO(v4.0): post errors to last keep alive message before closing
// (see https://github.com/coreos/etcd/pull/7866)
KeepAlive(ctx context.Context, id LeaseID) (<-chan *LeaseKeepAliveResponse, error)
// KeepAliveOnce renews the lease once. The response corresponds to the
// first message from calling KeepAlive. If the response has a recoverable
// error, KeepAliveOnce will retry the RPC with a new keep alive message.
//
// In most of the cases, Keepalive should be used instead of KeepAliveOnce.
KeepAliveOnce(ctx context.Context, id LeaseID) (*LeaseKeepAliveResponse, error)
// Close releases all resources Lease keeps for efficient communication
// with the etcd server.
Close() error
}
lease 是分散式系統中一個常見的概念,用於代表一個分散式租約。典型情況下,在分散式系統中需要去檢測一個節點是否存活的時,就需要租約機制。
Grant方法用於建立一個租約,當伺服器在給定 time to live 時間內沒有接收到 keepAlive 時租約過期;Revoke撤銷一個租約,所有附加到租約的key將過期並被刪除;TimeToLive 獲取租約資訊;KeepAlive 通過從客戶端到伺服器端的流化的 keep alive 請求和從伺服器端到客戶端的流化的 keep alive 應答來維持租約;檢測分散式系統中一個程序是否存活,可以在程序中去建立一個租約,並在該程序中週期性的呼叫 KeepAlive 的方法。如果一切正常,該節點的租約會一致保持,如果這個程序掛掉了,最終這個租約就會自動過期,在 etcd 中,允許將多個 key 關聯在同一個 lease 之上,可以大幅減少 lease 物件重新整理帶來的開銷。
watch相關介面:
type Watcher interface {
// Watch watches on a key or prefix. The watched events will be returned
// through the returned channel. If revisions waiting to be sent over the
// watch are compacted, then the watch will be canceled by the server, the
// client will post a compacted error watch response, and the channel will close.
// If the context "ctx" is canceled or timed out, returned "WatchChan" is closed,
// and "WatchResponse" from this closed channel has zero events and nil "Err()".
// The context "ctx" MUST be canceled, as soon as watcher is no longer being used,
// to release the associated resources.
//
// If the context is "context.Background/TODO", returned "WatchChan" will
// not be closed and block until event is triggered, except when server
// returns a non-recoverable error (e.g. ErrCompacted).
// For example, when context passed with "WithRequireLeader" and the
// connected server has no leader (e.g. due to network partition),
// error "etcdserver: no leader" (ErrNoLeader) will be returned,
// and then "WatchChan" is closed with non-nil "Err()".
// In order to prevent a watch stream being stuck in a partitioned node,
// make sure to wrap context with "WithRequireLeader".
//
// Otherwise, as long as the context has not been canceled or timed out,
// watch will retry on other recoverable errors forever until reconnected.
//
// TODO: explicitly set context error in the last "WatchResponse" message and close channel?
// Currently, client contexts are overwritten with "valCtx" that never closes.
// TODO(v3.4): configure watch retry policy, limit maximum retry number
// (see https://github.com/etcd-io/etcd/issues/8980)
Watch(ctx context.Context, key string, opts ...OpOption) WatchChan
// RequestProgress requests a progress notify response be sent in all watch channels.
RequestProgress(ctx context.Context) error
// Close closes the watcher and cancels all watch requests.
Close() error
}
etcd 的Watch 機制可以實時地訂閱到 etcd 中增量的資料更新,watch 支援指定單個 key,也可以指定一個 key 的字首。Watch 觀察將要發生或者已經發生的事件,輸入和輸出都是流;輸入流用於建立和取消觀察,輸出流傳送事件。一個觀察 RPC 可以在一次性在多個key範圍上觀察,併為多個觀察流化事件,整個事件歷史可以從最後壓縮修訂版本開始觀察。
ETCD資料版本機制
etcd資料版本中主要有term表示leader的任期,revision 代表的是全域性資料的版本。當叢集發生 Leader 切換,term 的值就會 +1,在節點故障,或者 Leader 節點網路出現問題,再或者是將整個叢集停止後再次拉起,都會發生 Leader 的切換;當資料發生變更,包括建立、修改、刪除,其 revision 對應的都會 +1,在叢集中跨 Leader 任期之間,revision 都會保持全域性單調遞增,叢集中任意一次的修改都對應著一個唯一的 revision,因此我們可以通過 revision 來支援資料的 MVCC,也可以支援資料的 Watch。
對於每一個 KeyValue 資料節點,etcd 中都記錄了三個版本:
- 第一個版本叫做 create_revision,是 KeyValue 在建立時對應的 revision;
- 第二個叫做 mod_revision,是其資料被操作的時候對應的 revision;
- 第三個 version 就是一個計數器,代表了 KeyValue 被修改了多少次。
在同一個 Leader 任期之內,所有的修改操作,其對應的 term 值始終相等,而 revision 則保持單調遞增。當重啟叢集之後,所有的修改操作對應的 term 值都加1了。
ETCD之MVCC併發控制
說起mvcc大家都不陌生,mysql的innodb中就使用mvcc實現高併發的資料訪問,對資料進行多版本處理,並通過事務的可見性來保證事務能看到自己應該看到的資料版本,同樣,在etcd中也使用mvcc進行併發控制。
etcd支援對同一個 Key 發起多次資料修改,每次資料修改都對應一個版本號。etcd記錄了每一次修改對應的資料,即一個 key 在 etcd 中存在多個歷史版本。在查詢資料的時候如果不指定版本號,etcd 會返回 Key 對應的最新版本,同時etcd 也支援指定一個版本號來查詢歷史資料。
etcd將每一次修改都記錄下來,使用 watch訂閱資料時,可以支援從任意歷史時刻(指定 revision)開始建立一個 watcher,在客戶端與 etcd 之間建立一個數據管道,etcd 會推送從指定 revision 開始的所有資料變更。etcd 提供的 watch 機制保證,該 Key 的資料後續的被修改之後,通過這個資料管道即時的推送給客戶端。
分析其原始碼可知:
type revision struct {
// main is the main revision of a set of changes that happen atomically.
main int64
// sub is the the sub revision of a change in a set of changes that happen
// atomically. Each change has different increasing sub revision in that
// set.
sub int64
}
func (a revision) GreaterThan(b revision) bool {
if a.main > b.main {
return true
}
if a.main < b.main {
return false
}
return a.sub > b.sub
}
在etcd的mvcc實現中有一個revision結構體,main 表示當前操作的事務 id,全域性自增的邏輯時間戳,sub 表示當前操作在事務內部的子 id,事務內自增,從 0 開始;通過GreaterThan方法進行事務版本的比較。
ETCD儲存資料結構
etcd 中所有的資料都儲存在一個 btree的資料結構中,該btree儲存在磁碟中,並通過mmap的方式對映到記憶體用來支援快速的訪問,treeIndex的定義如下:
type treeIndex struct {
sync.RWMutex
tree *btree.BTree
}
func newTreeIndex() index {
return &treeIndex{
tree: btree.New(32),
}
}
index所繫結對btree的操作有Put、Get、Revision、Range及Visit等,以Put方法為例,其原始碼如下:
func (ti *treeIndex) Put(key []byte, rev revision) {
keyi := &keyIndex{key: key}
ti.Lock()
defer ti.Unlock()
item := ti.tree.Get(keyi)
if item == nil {
keyi.put(rev.main, rev.sub)
ti.tree.ReplaceOrInsert(keyi)
return
}
okeyi := item.(*keyIndex)
okeyi.put(rev.main, rev.sub)
}
通過原始碼可知對btree資料的讀寫操作都是在加鎖下完成的,從而來保證併發下資料的一致
版权声明
本文为[itread01]所创,转载请带上原文链接,感谢
https://www.itread01.com/content/1604494985.html
边栏推荐
- C++ 数字、string和char*的转换
- C++学习——centos7上部署C++开发环境
- C++学习——一步步学会写Makefile
- C++学习——临时对象的产生与优化
- C++学习——对象的引用的用法
- C++编程经验(6):使用C++风格的类型转换
- Won the CKA + CKS certificate with the highest gold content in kubernetes in 31 days!
- C + + number, string and char * conversion
- C + + Learning -- capacity() and resize() in C + +
- C + + Learning -- about code performance optimization
猜你喜欢
-
C + + programming experience (6): using C + + style type conversion
-

Latest party and government work report ppt - Park ppt
-
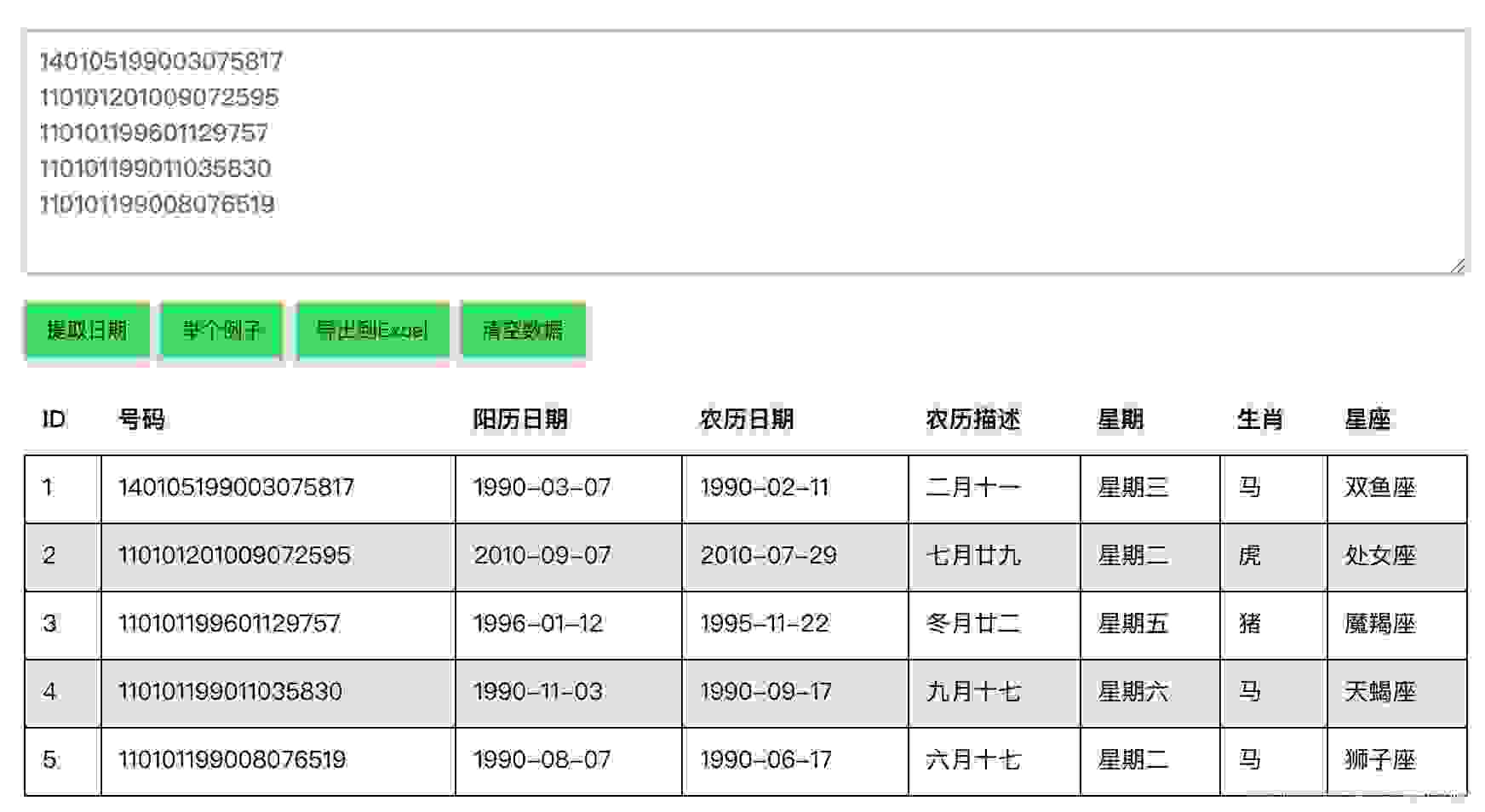
在线身份证号码提取生日工具
-
Online ID number extraction birthday tool
-
️野指针?悬空指针?️ 一文带你搞懂!
-
Field pointer? Dangling pointer? This article will help you understand!
-
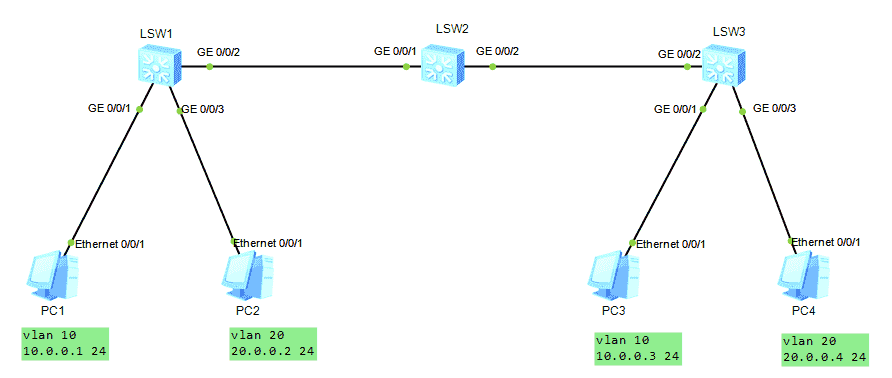
HCNA Routing&Switching之GVRP
-
GVRP of hcna Routing & Switching
-

Seq2Seq实现闲聊机器人
-
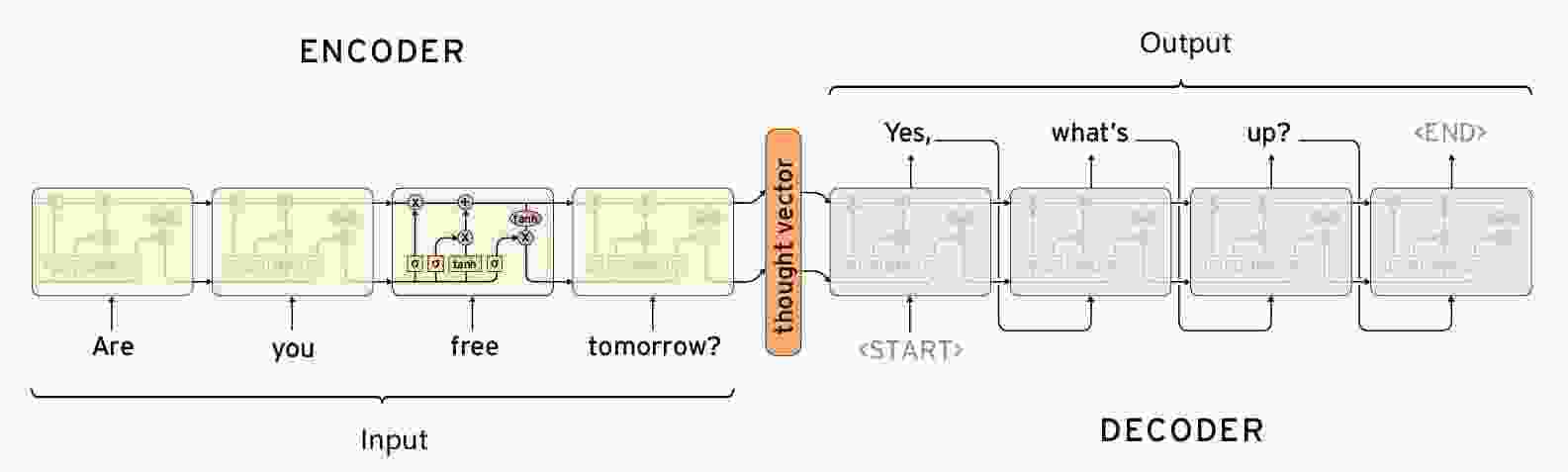
【闲聊机器人】seq2seq模型的原理
随机推荐
- LeetCode 91. 解码方法
- Seq2seq implements chat robot
- [chat robot] principle of seq2seq model
- Leetcode 91. Decoding method
- HCNA Routing&Switching之GVRP
- GVRP of hcna Routing & Switching
- HDU7016 Random Walk 2
- [Code+#1]Yazid 的新生舞会
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- HDU7016 Random Walk 2
- [code + 1] Yazid's freshman ball
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- Qt Creator 自动补齐变慢的解决
- HALCON 20.11:如何处理标定助手品质问题
- HALCON 20.11:标定助手使用注意事项
- Solution of QT creator's automatic replenishment slowing down
- Halcon 20.11: how to deal with the quality problem of calibration assistant
- Halcon 20.11: precautions for use of calibration assistant
- “十大科学技术问题”揭晓!|青年科学家50²论坛
- "Top ten scientific and technological issues" announced| Young scientists 50 ² forum
- 求反转链表
- Reverse linked list
- js的数据类型
- JS data type
- 记一次文件读写遇到的bug
- Remember the bug encountered in reading and writing a file
- 单例模式
- Singleton mode
- 在这个 N 多编程语言争霸的世界,C++ 究竟还有没有未来?
- In this world of N programming languages, is there a future for C + +?
- es6模板字符
- js Promise
- js 数组方法 回顾
- ES6 template characters
- js Promise
- JS array method review
- 【Golang】️走进 Go 语言️ 第一课 Hello World
- [golang] go into go language lesson 1 Hello World