当前位置:网站首页>Python爬蟲實戰詳解:爬取圖片之家
Python爬蟲實戰詳解:爬取圖片之家
2020-11-06 01:17:51 【itread01】
前言
本文的文字及圖片來源於網路,僅供學習、交流使用,不具有任何商業用途,版權歸原作者所有,如有問題請及時聯絡我們以作處理
如何使用python去實現一個爬蟲?
- 模擬瀏覽器
請求並獲取網站資料
在原始資料中提取我們想要的資料 資料篩選
將篩選完成的資料做儲存
完成一個爬蟲需要哪些工具
- Python3.6
- pycharm 專業版
目標網站
圖片之家
https://www.tupianzj.com/
爬蟲程式碼
匯入工具
python 自帶的標準庫
import ssl
系統庫 自動建立儲存資料夾
import os
下載包
import urllib.request
網路庫 第三方包
import requests
網頁選擇器
from bs4 import BeautifulSoup
預設請求https網站不需要證書認證
ssl._create_default_https_context = ssl._create_unverified_context
模擬瀏覽器
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
}
自動建立資料夾
if not os.path.exists('./插畫素材/'):
os.mkdir('./插畫素材/')
else:
pass
請求操作
url = 'https://www.tupianzj.com/meinv/mm/meizitu/' html = requests.get(url, headers=headers).text
對頁面原始資料做資料提取
soup = BeautifulSoup(html, 'lxml')
images_data = soup.find('ul', class_='d1 ico3').find_all_next('li')
for image in images_data:
image_url = image.find_all('img')
for _ in image_url:
print(_['src'], _['alt'])
下載
try:
urllib.request.urlretrieve(_['src'], './插畫素材/' + _['alt'] + '.jpg')
except:
pass
效果圖
版权声明
本文为[itread01]所创,转载请带上原文链接,感谢
https://www.itread01.com/content/1604499424.html
边栏推荐
- C++ 数字、string和char*的转换
- C++学习——centos7上部署C++开发环境
- C++学习——一步步学会写Makefile
- C++学习——临时对象的产生与优化
- C++学习——对象的引用的用法
- C++编程经验(6):使用C++风格的类型转换
- Won the CKA + CKS certificate with the highest gold content in kubernetes in 31 days!
- C + + number, string and char * conversion
- C + + Learning -- capacity() and resize() in C + +
- C + + Learning -- about code performance optimization
猜你喜欢
-
C + + programming experience (6): using C + + style type conversion
-

Latest party and government work report ppt - Park ppt
-
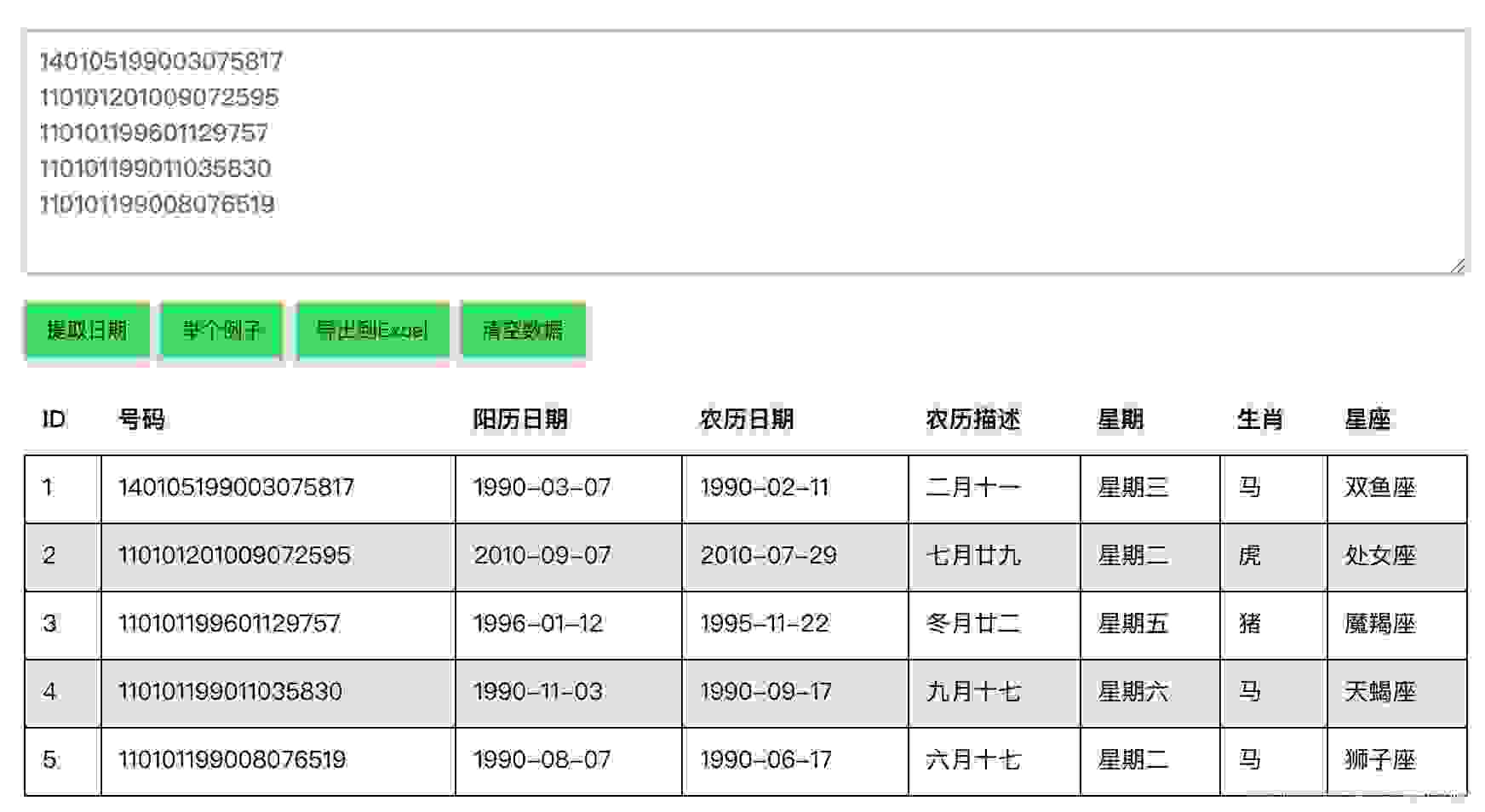
在线身份证号码提取生日工具
-
Online ID number extraction birthday tool
-
️野指针?悬空指针?️ 一文带你搞懂!
-
Field pointer? Dangling pointer? This article will help you understand!
-
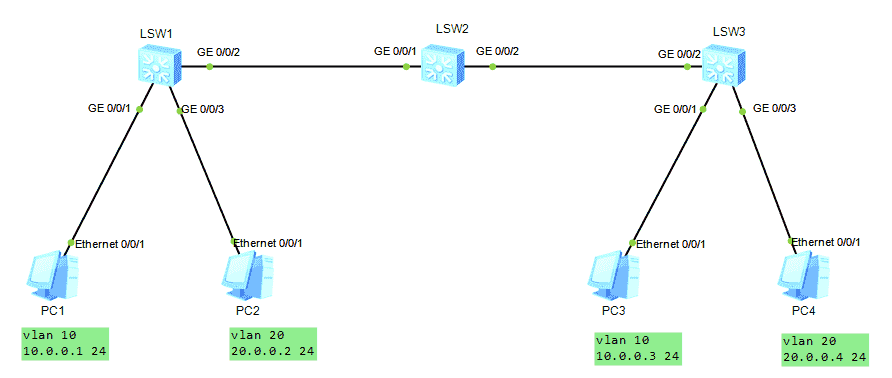
HCNA Routing&Switching之GVRP
-
GVRP of hcna Routing & Switching
-

Seq2Seq实现闲聊机器人
-
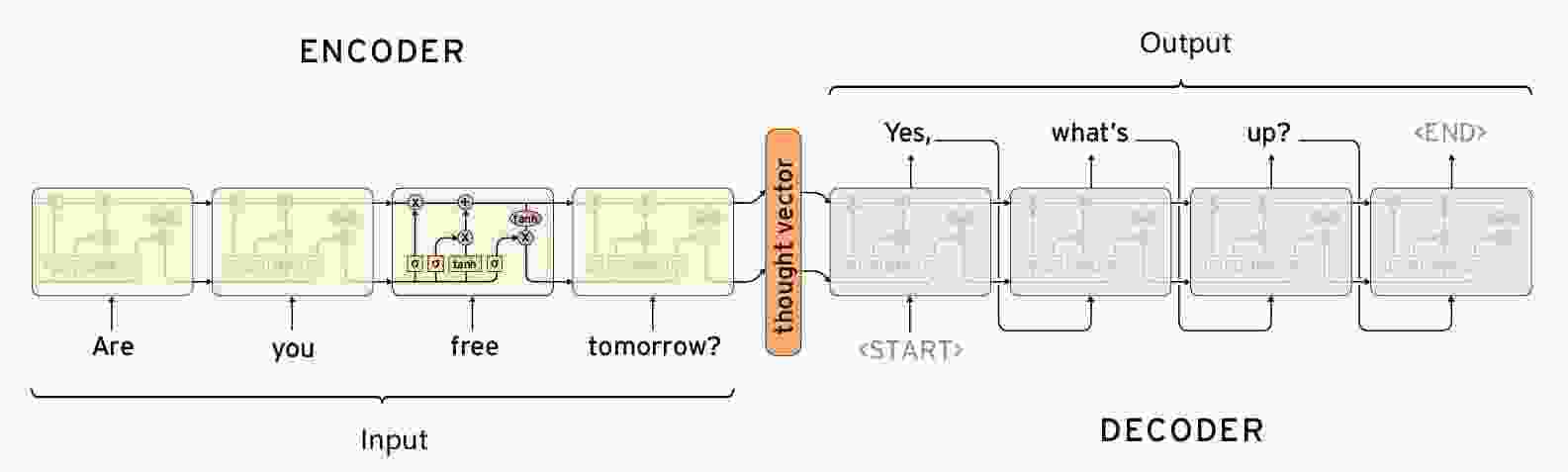
【闲聊机器人】seq2seq模型的原理
随机推荐
- LeetCode 91. 解码方法
- Seq2seq implements chat robot
- [chat robot] principle of seq2seq model
- Leetcode 91. Decoding method
- HCNA Routing&Switching之GVRP
- GVRP of hcna Routing & Switching
- HDU7016 Random Walk 2
- [Code+#1]Yazid 的新生舞会
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- HDU7016 Random Walk 2
- [code + 1] Yazid's freshman ball
- CF1548C The Three Little Pigs
- HDU7033 Typing Contest
- Qt Creator 自动补齐变慢的解决
- HALCON 20.11:如何处理标定助手品质问题
- HALCON 20.11:标定助手使用注意事项
- Solution of QT creator's automatic replenishment slowing down
- Halcon 20.11: how to deal with the quality problem of calibration assistant
- Halcon 20.11: precautions for use of calibration assistant
- “十大科学技术问题”揭晓!|青年科学家50²论坛
- "Top ten scientific and technological issues" announced| Young scientists 50 ² forum
- 求反转链表
- Reverse linked list
- js的数据类型
- JS data type
- 记一次文件读写遇到的bug
- Remember the bug encountered in reading and writing a file
- 单例模式
- Singleton mode
- 在这个 N 多编程语言争霸的世界,C++ 究竟还有没有未来?
- In this world of N programming languages, is there a future for C + +?
- es6模板字符
- js Promise
- js 数组方法 回顾
- ES6 template characters
- js Promise
- JS array method review
- 【Golang】️走进 Go 语言️ 第一课 Hello World
- [golang] go into go language lesson 1 Hello World